Shell 是一个供我们操作应用程序接口的程序,隔离保护内核。
Bash 是 Shell 的一个解释器,可以理解为 Shell 的一种 文本模式 的实现。广义上讲,图形用户接口也是 Shell 程序。可以查看
/etc/shells文件,记录了系统可用的多个 shell 实现,一般情况下默认使用 Bash。
变量及运算
定义变量
直接使用 k=v(中间不能有空格)来定义变量,当定义的变量中有空格时,需要使用双引号/单引号括起来。
name=zhangsan
a="hello world"规则:
-
命名可以包含字母数字下划线,但是不能以数字开头。
-
变量 默认都是字符串类型,不能进行运算。
-
双引号和单引号的区别在于,单引号只保留纯文本。
var=world echo "hello $var" # hello world echo 'hello $var' # 原样输出 -
还有反单引号 ` 和 $(),用于在一串指令中引用其他指令。
version=$(uname -r) version=`uname -r` echo $version -
转义字符
\将特殊字符变为一般字符。 -
想要追加内容时,使用
:PATH="$PATH":/home/bin PATH=${PATH}:/home/bin -
使用
export varName提升为全局变量,适用于本次登录。 -
使用
unset取消变量。 -
想要下次登录时变量还生效,可以将变量定义在
~/.bashrc下。
键盘读入数据:read [-pt] var
# -p 描述性信息
# -t 等待的秒数,超时跳过
read -p "please enter your name: " -t 30 name
echo $name声明变量类型:declare/typeset [-aixr] var
# -a 将后面的变量定义为 array 类型
# -i 定义为 integer 整形
# -x 声明为全局变量
# -r 声明为只读类型
sum=1+2+3+4
echo $sum # 1+2+3+4
declare -i sum=1+2+3+4
echo $sum # 10
# 将-变为+ 可以取消声明的类型
declare +i sum显示变量
使用 echo 来显示变量,需要加上 $,{} 为可选。
echo $PATH
echo ${PATH}几个特殊的变量:
$n:n 为数字,$0 表示脚本名称,>0 表示脚本接受的第几个参数,两位以上时需要使用{}包裹数字,如${10}。$#:表示脚本接收的参数数量。$*、$@:都是接收所有参数,前者将参数作为一个整体接收,后者将参数分开接收。$?:上一条命令返回的状态。
操作变量
-
从前往后删除变量内容:
#表示从变量内容的最前面开始向后删除,且删除 最短 的匹配项。##表示从变量内容的最前面开始向后删除,且删除 最长 的匹配项。
path=${PATH} echo ${path#/*local/bin:} # /usr/local/bin:/usr/bin:/home... echo ${path##/*:} # /home... -
从后往前删除使用
%# 举例: aa/bb/cc/dd # 拿到文件路径 echo ${MAIL##/*/} # aa/bb/cc # 拿到文件名 echo ${MAIL%/*} # dd -
取代功能
${var/old/new}# 将 path 中的第一个 aa 替换为 bb echo ${path/aa/bb} # 将 path 中的所有 aa 替换为 bb echo ${path//aa/bb} -
替换功能
# 当username不存在时,取root为值。 username=${username-root} # 当username不存在或不为空串时,取root为值。 username=${username:-root}
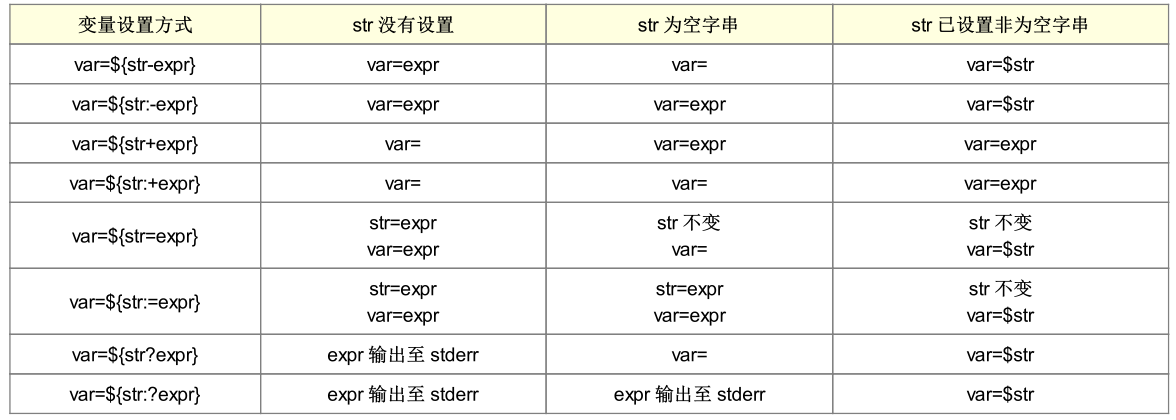
运算与判断
语法:$((表达式)) 或 $[表达式]。
运算符:expr + = \* / % (注意乘号前加了反斜杠)
expr 1 + 1 #注意有空格
expr `expr 1 + 1` \* 2 #(1+1)*2
expr $[(1+1)*2] #(1+1)*2逻辑运算:[ 表达式 ](注意表达式两边有空格)
判断条件:
-
条件为空表示 false,可以使用 && ||。
-
= -lt -le -eq -gt -ge -ne 判断数量关系
$[ 1 -lt 2 ] # 1<2 -
-r -w -x 判断文件权限
$[ -w hello.sh ] # 是否有对hello.sh的写权限 -
-f -e -d 判断文件是否存在
#-d 文件存在且是一个目录 #-f 文件存在并且是一个常规文件 #-e 文件存在不论是文件还是目录 $[ -f /hello.sh ] #当前目录下时候有hello.sh文件
其他常用功能
数据流重定向
默认情况下,标准输出 stdout、标准错误输出 stderr,都是输出到屏幕上。
几个符号:
-
标准输入:< 或 << (两个表示追加)
-
标准输出:> 或 >>
-
标准错误输出:2> 或 2>>
说明:为什么是 2 ,因为上面三个的代码分别为 0、1、2。
ll / # 屏幕上列出文件信息
ll / > ~/rootfile # 屏幕上无信息,重定向输出到了文件中
ll /home > ~/rootfile # 发现文件内容被替换
ll /home >> ~/rootfile ## 使用两个>表示追加管道命令
xxx | [指令],接收并处理前一个 指令传来的 stdout 信息,不能直接接收处理 stderr。[指令] 必须是能接收 stdin 的指令,如 less, more, head, tail,而 ls, cp, mv 等就不是管道命令。
截取:cut、grep
这两个命令都是 逐行处理。
- cut:
# -d ['分隔符']
# -f [n] # 与 -d 连用,表示取出第几段,从1开始
# -c [区间] # 以字符为单位截取固定的区间
# 以 “:” 分隔,取出第五个(有点像 split)
echo ${PATH} | cut -d ':' -f 5
# 也可以取多个
echo ${PATH} | cut -d ':' -f 1,2,3
# 输出从第12个字符开始往后的数据
export | cut -c 12-- grep:
# 逐行处理,有'root'则输出
last | grep 'root'
# 无'root'则输出
last | grep -v 'root'
# 找出abc.conf中含有'root'的行高亮输出
grep --color=auto 'root' /etc/abc.conf排序:sort、wc、uniq
-
sort:(与字符集编码有关)
sort [-fbMnrtuk] [file or stdin] # -f 忽略大小写 # -b 忽略最前面的空白字符部分 # -M 以月份的名字来排序,例如 JAN, DEC 等等 # -n 使用数字进行排序 # -r 反向排序 # -u 即 uniq,去重 # -t '分隔符',默认是以tab分隔,类似于 cut 的 -d # -k 以第几段作为关键字排序,类似于 cut 的 -f # 以 : 分隔后的第3个字段为关键字排序 cat /etc/passwd | sort -t ':' -k 3 -
**uniq:**去重
uniq [-ic] # -i 忽略带下写 # -c 统计个数 # 统计每个人登录的次数并排序 last | cut -d ' ' -f1 | sort | uniq -c -
**wc:**字符统计
wc [-lwm] # 默认全部列出 # -l 列出有多少行 # -w 列出有多少字(英文单字) # -m 列出有多少字符 # 列出 abc.txt 的统计信息 cat /etc/abc.txt | wc
双向重定向:tee
需求:将 stdout 输出到屏幕的同时,存入文件。
tee [-a] file
# -a 以append的方式写入文件
ls -l /home | tee -a ~/homefile | moresed 工具
按行处理。
sed [-nefi] [操作]
# -n 只将操作影响的行输出到屏幕
# -e 直接在指令列模式上进行 sed 操作
# -f file 将 sed 操作后的结果写入文件
# -i 直接修改文件内容而不是输出到屏幕
# ---操作说明---
# a str 新增到下一行
# i str 插入到上一行
# d 整行删除
# c 整行取代
# s /oldStr/newStr/g 部分数据取代或删除
# p 打印,通常与 -n 连用
# ---举例---
# 在第2行后新增一行
nl abc.txt | sed '2a hello world'
# 在第2行前新增两行,使用 \ 换行
nl abc.txt | sed '2i hello \ world'
# 删除第2-最后一行 $代表最后一行
nl abc.txt | sed '2,$d'
# 将第2-5行整行取代
nl abc.txt | sed '2,5c lalala'
# 打印 11-20 行
nl abc.txt | head -n 20 | tail -n 10
nl abc.txt | sed -n '11,20p'awk 工具
将一行分成几段处理,默认分隔符为空格或 tab。
awk '条件{操作} 条件{操作} ...' file
# $0 代表一整行,$1 代表分隔后的第一个数据
# 取前5个登陆者,打印name和ip
# dmtsai pts/0 192.168.1.1 ...
last -n 5 | awk '{print $1 "\t" $3}'内置变量:
- NF:每一行的字段总数
- NR:当前是第几行
- FS:当前的分隔字符
逻辑判断符号:> < >= ⇐ == !=
开始和结束:
-
BEGIN:在开始前进行的操作。
# 开始前设置分隔符为 : | awk 'BEGIN {FS=":"}' -
END:在结束时进行的操作。
举例:
# Name 1st 2nd 3th
# VBird 23000 24000 25000
# DMTsai 21000 20000 23000
# Bird2 43000 42000 41000
# 取出数据并计算总和
| awk 'NR==1 {printf "%10s %10s %10s %10s %10s\n",$1,$2,$3,$4,"Total"} \
NR>=2{total = $2 + $3 + $4} \
printf "%10s %10d %10d %10d %10.2f\n", $1, $2, $3, $4, total}'Shell 脚本
Hello World
#!/bin/bash
# balabala
echo "Hello world"
exit 0#!/bin/bash
read -p "Please input your first name: " firstname
read -p "Please input your last name: " lastname
echo -e "\nYour full name is: ${firstname} ${lastname}"说明:
- 第一行声明该脚本使用哪个 shell 执行。
除了第一行的 #! ,其他的 # 都是注释。 exit 0表示 return 0 ,可以不要。
流程控制
运算符和条件判断等在第一部分变量部分记录过了。
IF
# 简单的 if
if [ condition ]; then
echo "true"
exit 0
fi
# if-else
if [ condition ]; then
echo "true"
exit 0
else
echo "false"
exit 1
fi
# if-elif
if [ condition ]; then
echo "1"
elif [ condition ]; then
echo "2"
else
echo "3"
fiCASE
case $var in
"1")
echo "a"
;;
"2")
echo "b"
;;
*)
exit 1
;;
esac WHILE
while [ condition ]
do
# doSth
done
until [ condition ]
do
# doSth
doneFOR
for var in con1 con2 con3 ...
do
# doSth
done
for (( i=1; i<=${n}; i=i+1 ))
do
# doSth
done函数
# $0 表示函数名,$1 之后表示参数
function fname() {
# doSth
}