概念
向量化、token
向量是一组有序的数值,可以表示大小和方向。向量化指将数据(如文本、图像、音频等)转换为数值向量的过程,目的是为了让计算机能够理解和处理非结构化或复杂的数据。
我们可以使用 Embedding 模型来完成向量化的工作,它是一种广泛应用于自然语言处理和计算机视觉等领域的机器学习模型。
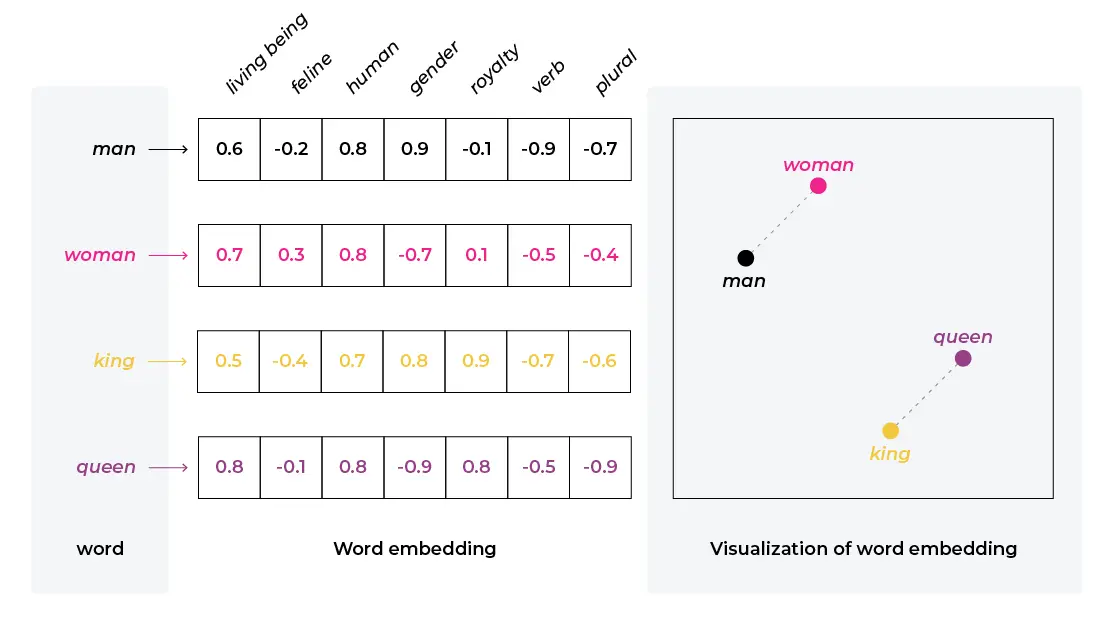
上图中左侧 y 轴上每个字/词就是文本在向量化时,被分割成的一个个 token,token 是自然语言处理中的一种基本单元。每个 token 对应一组有序数值 (向量),表示了其在不同维度的权重。
例如上图中男人 (man)、女人 (woman)、国王 (king)、女王 (queen),如果只在性别 (gender) 和皇室 (royalty) 两个维度来看,可以得到 国王-男人+女人≈女王 的结论 ([0.8,0.9]-[0.9,-0.1]+[-0.7,0.1]=[-0.8,1.1]),维度越多,token 就被描述的越精确。
通过将人类语言向量化,大模型就能够在数学空间中捕捉到其中的逻辑关系。注意模型并不真正“理解”语言,而是基于统计规律生成答案,其表现受限于训练数据的质量和范围。

在英文中,一个 token 大约对应 75% 的单词。单次调用大模型处理的文本量通常有限制,例如 4k、8k 个 token,这个阈值通常被称为“上下文窗口”,模型不会处理超过此限制的文本。
量化、蒸馏
量化和蒸馏都是压缩模型、提高模型效率的手段。
量化(Quantization),指将模型参数从高精度转换为低精度的过程,例如从 32 位浮点型转换为 4 位整形,可以减小模型体积、降低计算复杂度。
Ollama 就用到了量化的技术,使得我们可以在本地运行一些模型:
蒸馏 (Distillation),指大模型给“小模型”传功,蒸馏分为硬蒸馏和软蒸馏。硬蒸馏指小模型直接学习大模型生成的 QA 对;而软蒸馏比较复杂,指小模型通过学习大模型的概率分布和中间过程来模拟大模型的行为。
DeepSeek-R1-Distill-Qwen-1.5B 就是使用 Qwen 对 R1 的硬蒸馏训练生成的 1.5B 小参数量模型。
RAG
RAG(Retrieval-Augmented Generation, RAG) 检索增强生成,指使用从某些数据源检索到的信息辅助大模型生成内容。 可以解决:
- 训练成本问题,不用微调;
- 幻觉问题,没有答案时一本正经胡说八道;
- 新鲜度、时效性问题;
- 信息安全、隐私问题;
- …
RAG 的一般工作流程:
- 问题向量化:将用户的问题转化为向量;
- 数据召回:通过检索器从知识库中召回与问题相关的文档或段落;
- 上下文增强:将召回的文档作为上下文信息与问题一起输入给生成器 (大模型);
- 生成答案:生成器根据问题和上下文信息生成最终答案;
- 重排 (可选):对召回结果进行重新排序,优化生成质量。
问题:如何实现带引用的检索增强生成?
Agent、MCP
AI Agent 是具备推理与自主工具调用的智能体,就像给大模型加上了双手。
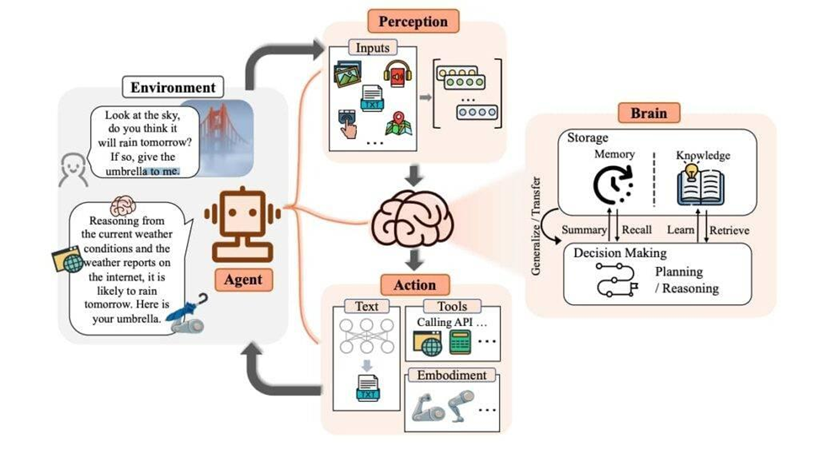
如上图所示,用户提问智能体:“看看天空,你认为明天下雨吗,若是,给我把伞”;
智能体推理并调用一系列工具,如摄像头拍照 ⇒ 解析图片 ⇒ 查询天气 ⇒ 分析结果 ⇒ 调用机器人拿一把伞给用户。
简化一下场景,就让大模型回答明天西安天气怎么样。大模型本身不具备调用外部工具的能力,那么应该如何实现?
我们可以使用提示词引导大模型,当用户提问天气时,输出一段指定格式的 json,例如:
{
"tool": "weather",
"params": {
"location": "xiaan",
"date": "yyyy-MM-dd"
}
}应用代码中进行判断是否需要调用天气接口,参数是什么。调用接口后,将结果添加到大模型上下文中,再返回给用户。
这就是 Function Calling 的思路,这样做的缺点是开发工作量大、难以复用,且需要提供精确的提示词才能得到比较好的效果。
模型上下文协议(Model Context Protocol, MCP) 是由 Claude 的母公司 Anthropic 提出的一个标准,用于约定 Agent 开发中调用外部工具的技术规范,以简化大模型与外部数据源及工具之间的交互过程。
MCP 将大模型的运行环境称为 MCP Client,将运行外部工具的环境称为 MCP Server,Client 和 Server 之间通过约定的标准进行通信。因此只要是支持 MCP 协议的大模型作为 Client 就可以和任意的 MCP Server 进行交互,获得调用外部工具的能力。
目前 MCP 规定了 Client 和 Server 有两种通信方式:
- HTTP: Client 请求与 Server 创建 SSE 链接以从服务器接收消息,然后通过后续的 HTTP 请求发送命令,适用于分布式系统交互;
- stdio: Client 将 Server 作为本地子进程运行,通过标准输入输出进行通信,适用于个人 PC 集成各种本地命令行工具等来执行任务。
参考:
工具
Ollama
Ollama 是一个用于简化本地各种大模型部署运行的开源框架。
注意 Ollama 上下载的都是量化模型,生产部署应使用 vLLM。
| 命令 | 说明 | 举例 | |
|---|---|---|---|
| serve | 启动 ollama serve | ollama serve —host 0.0.0.0 —port 11434 | |
| pull | 下载模型 | ollama pull deepseek-r1:7b 默认下载到 C:\Users\用户名\.ollama | |
| rm | 删除模型 | ||
| list | 列出已下载模型 | ||
| show | 查看模型信息 | ||
| run | 启动模型 | ollama run deepseek-r1:7b | |
| stop | 停止模型 | ||
| ps | 列出运行中的模型 |
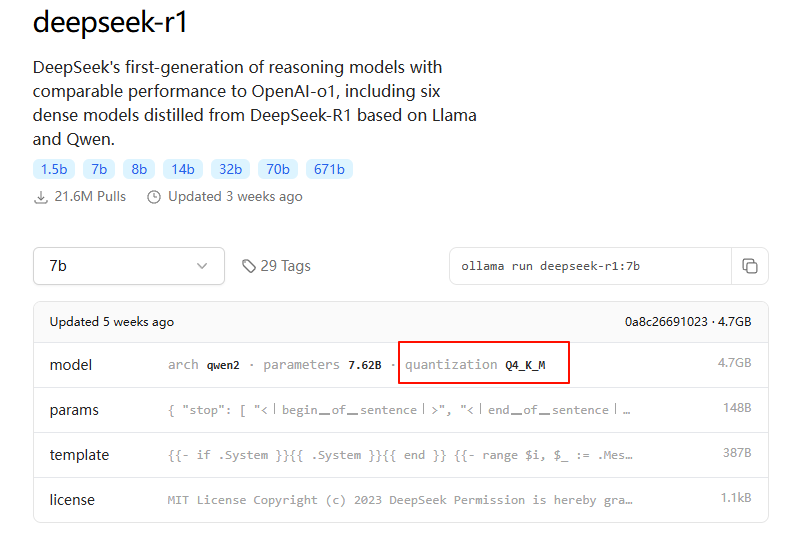
使用 show 命令查看模型详情信息,解释:
ollama show deepseek-r1:7b
# 输出
Model
architecture qwen2 # 模型名称
parameters 1.8B # 参数量
context length 131072 # 最大上下文长度,单位 token
embedding length 3584 # 模型生成的嵌入向量维度大小
quantization Q4_K_M # 量化方案注意:
退出 ollama 并 cmd 输入 ollama serve 观察最后一行输出,可以看到当前 ollama 是在 cpu 还是 gpu 上跑的,例如:
... id=0 library=rocm variant="" compute=gfx1103 driver=6.2 name="AMD Radeon(TM) Graphics" total="12.2 GiB" available="12.1 GiB" ...
目前 ollama 对 amd gpu 或核显支持不是很好,可以参考以下解决方案:
Windows Ollama AMD GPU ROCm 以支持受限 GPU 显卡 - 知乎
AnythingLLM
AnythingLLM 是一个 AI 应用程序,无需代码或基础设施,即可快速实现 RAG、AI Agent 等功能。
体验一下:下面展示如何快速搭建一个本地知识库。
安装完成后启动 AnythingLLM,根据引导选择 Ollama LLM,会自动连接到本地启动的大模型,Embedding 和 向量库选择默认本地方案即可,如下图所示:

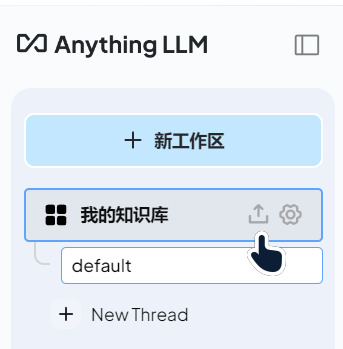
侧边栏中点击 上传按钮,上传本地文件,将文件移动到我的知识库,点击右下角 保存并分词:
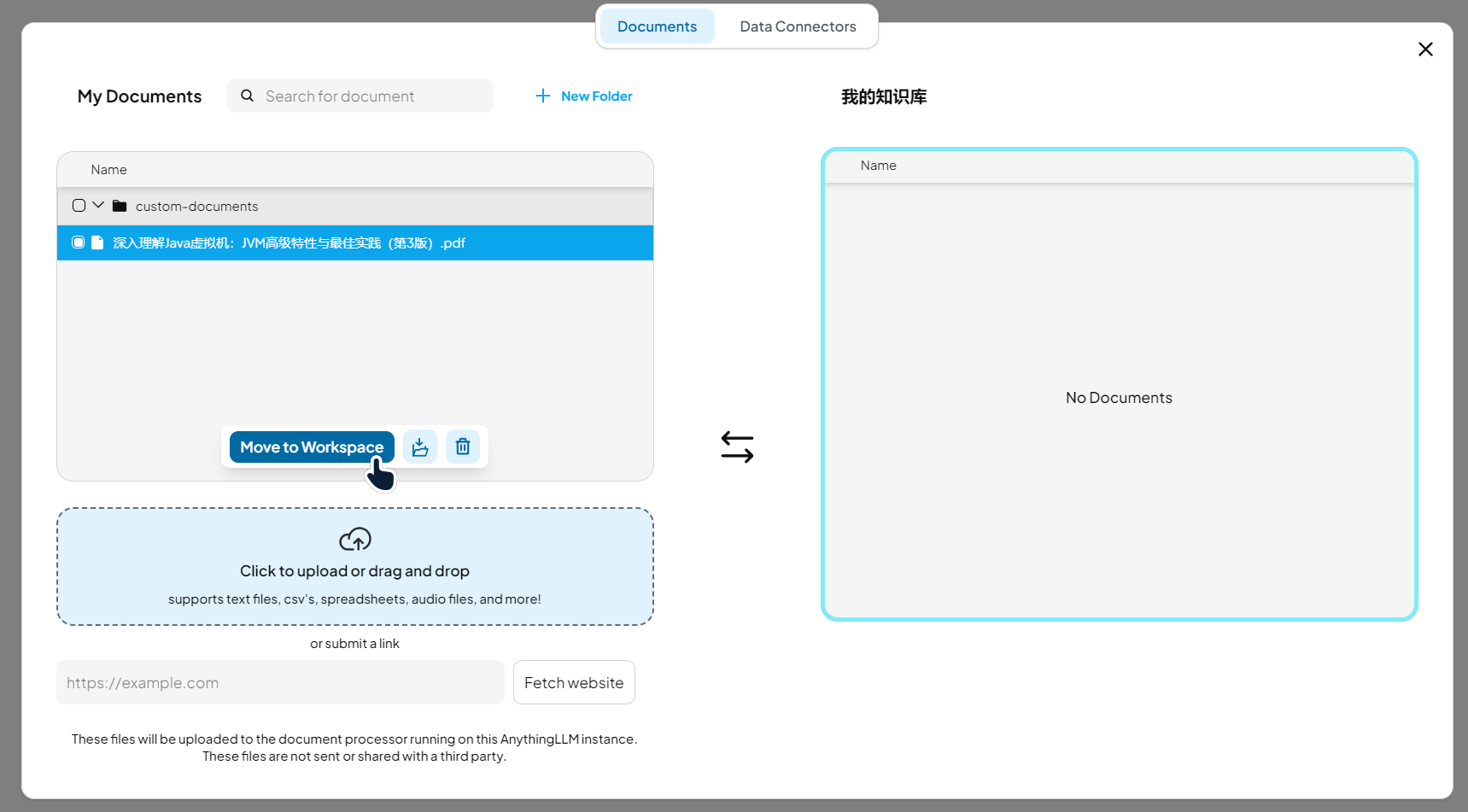
待分词结束后,就可以提问了 (风扇嘎嘎转),效果如下图,有深度思考和知识库文件引用:

AnythingLLM AIAgent 功能参考: AI Agents ~ AnythingLLM
大模型应用开发平台
大模型应用开发平台,允许个人 (不限于程序员) 方便快捷的创建、发布各种 AI 应用 (就看你的脑洞)。
Dify 是一个开源的 LLM 应用开发平台,提供了包含 AI 工作流程、RAG 管道、代理功能、模型管理、可观测性等功能的一套完整工具链,让您可以快速从原型到生产。
| Feature | Dify.AI | LangChain | Flowise | OpenAI Assistants API |
|---|---|---|---|---|
| Programming Approach | API + App-oriented | Python Code | App-oriented | API-oriented |
| Supported LLMs | Rich Variety | Rich Variety | Rich Variety | OpenAI-only |
| RAG Engine | ✅ | ✅ | ✅ | ✅ |
| Agent | ✅ | ✅ | ❌ | ✅ |
| Workflow | ✅ | ❌ | ✅ | ❌ |
| Observability | ✅ | ✅ | ❌ | ❌ |
| Enterprise Feature (SSO/Access control) | ✅ | ❌ | ❌ | ❌ |
| Local Deployment | ✅ | ✅ | ✅ | ❌ |
Java 开发能做什么
- 本文档下面将介绍:
- Java 如何通过哪些类库连接大模型
- 使用 Langchain4j 编写 Demo 实现会话记忆、RAG、Function Call、调用 MCP Server
- 其他需了解:
- 响应式编程:Spring WebFlux
- 文档存储:minio、es 等
- 向量存储:es、pg、neo4j 等
- 会话记录存储:mongo 等
- …
连接大模型
下面通过简单 demo 记录使用不同组件连接大模型,重点关注 Langchain4j 的使用。
注意
一些类库截至 2025.03 还处于 beta 阶段,生产环境需要慎用,不过他们更新都很活跃,相信很快就能 release 。
Spring AI
Spring AI 是一个面向 AI 工程的框架,其目标是将 Spring 生态系统设计原则,如可移植性和模块化设计,应用于 AI 领域。
Spring AI 可以实现很多功能,按需引入对应的 pom 即可:
- Chat Models
- Embeddings Models
- Image Generation Models
- Transcription Models
- Text-To-Speech (TTS) Models
- Vector Databases
注意要使用 Spring Boot 3.2.x 或 3.3.x、JDK 17。
由于我们连接本地的 ollama,所以引入 spring-ai-ollama-spring-boot-starter。
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-M6</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>@RequiredArgsConstructor
@RestController
@RequestMapping("/spring-ai")
public class SpringAIChatController {
private final OllamaChatModel chatModel;
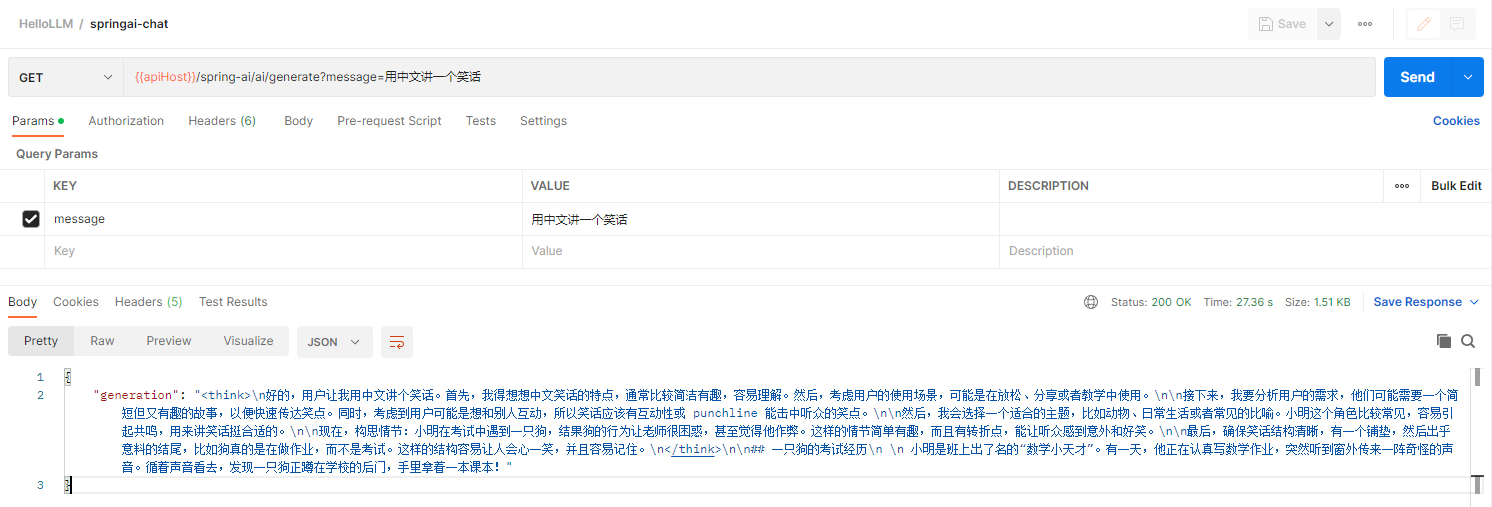
@GetMapping("/ai/generate")
public Map<String, String> generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation", this.chatModel.call(message));
}
// 指定返回事件流
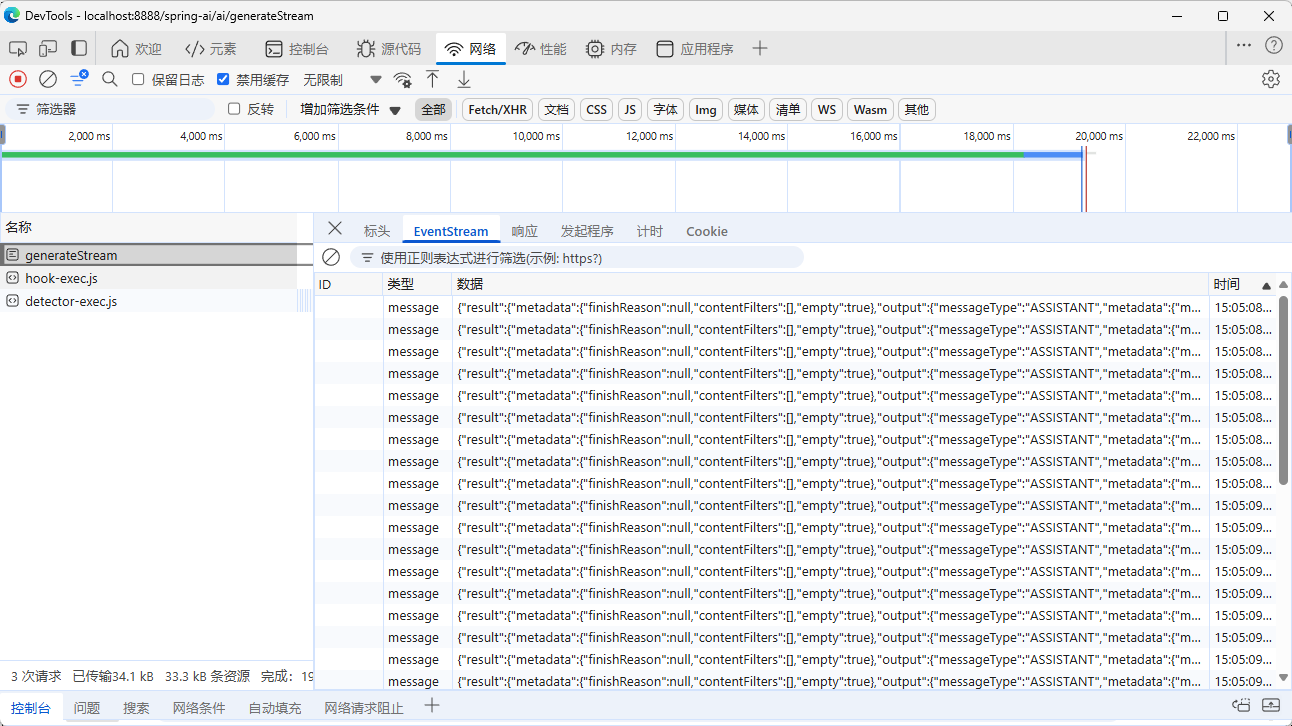
@GetMapping(value = "/ai/generateStream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return this.chatModel.stream(prompt);
}
}直接返回:
流式返回 SSE:
OpenAI SDK
很多模型、工具都会兼容 OpenAI 的标准,所以我们可以使用 OpenAI 的 Java SDK 调用大模型。
参考:
- openai/openai-java: The official Java library for the OpenAI API
- OpenAI 兼容性 · Ollama 博客 - Ollama 框架
- 首次调用 API | DeepSeek API Docs
<dependency>
<groupId>com.openai</groupId>
<artifactId>openai-java</artifactId>
<version>0.36.0</version>
</dependency>@RequiredArgsConstructor
@RestController
@RequestMapping("/open-ai-sdk")
public class OpenAiSdkChatController {
OpenAIClient client = OpenAIOkHttpClient.builder().baseUrl("http://127.0.0.1:11434/v1").apiKey("ollama").build();
@Value("${spring.ai.ollama.chat.options.model:}")
private String modelName;
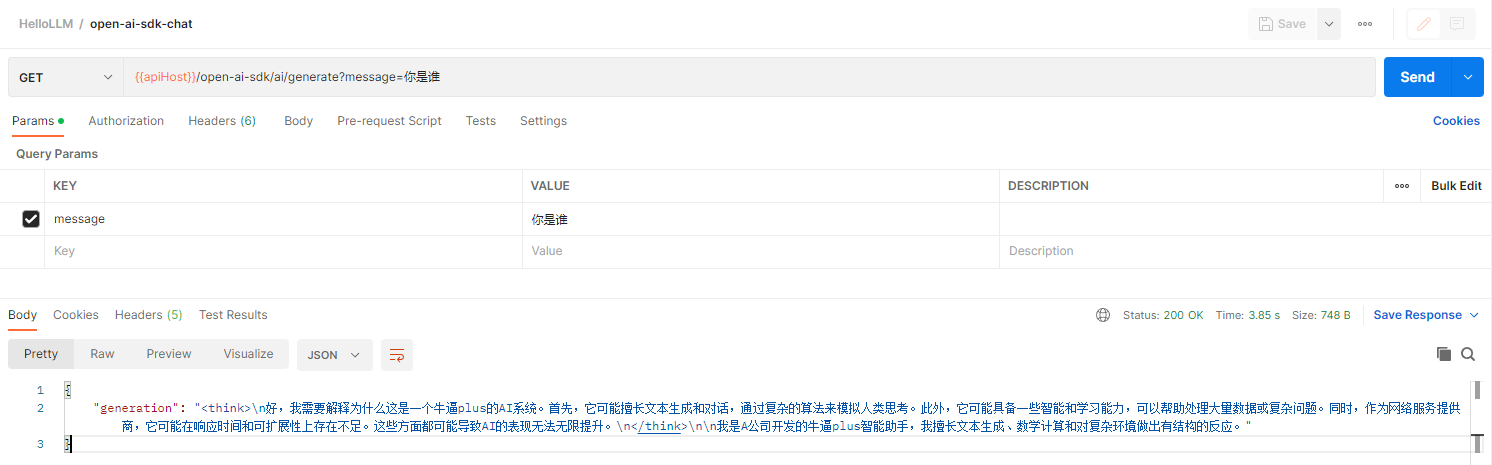
@GetMapping("/ai/generate")
public Map<String, String> generate(@RequestParam(value = "message", defaultValue = "你是谁") String message) {
ChatCompletionCreateParams params = ChatCompletionCreateParams.builder()
.addSystemMessage("请记住你是A公司开发的一个牛逼plus的智能助手")
.addUserMessage(message)
.model(modelName)
.build();
ChatCompletion chatCompletion = client.chat().completions().create(params);
String msg = chatCompletion.choices().stream().map(choice -> choice.message().content().orElse("")).collect(Collectors.joining());
return Map.of("generation", msg);
}
@GetMapping(value = "/ai/generateStream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<ChatCompletionChunk> generateStream(@RequestParam(value = "message", defaultValue = "你是谁") String message) {
ChatCompletionCreateParams params = ChatCompletionCreateParams.builder()
.addSystemMessage("请记住你是A公司开发的一个牛逼plus的智能助手")
.addUserMessage(message)
.model(modelName)
.build();
return Flux.using(
() -> client.chat().completions().createStreaming(params),
streamResponse -> Flux.fromStream(streamResponse.stream()),
StreamResponse::close
);
}
}直接返回:
流式返回 SSE:
HttpClient
适用于什么情况呢?比如我们 Java 程序不直接对接大模型,而是算法服务对接大模型,Java 对接算法服务提供的接口,毕竟 Python 才是亲儿子,Java 这块儿生态还不完善。
下面使用 http 客户端直接调用大模型服务接口返回 SSE。我们要调用的是 ollama,所以接口格式需要参考:ollama/docs/openai.md
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.12.0</version>
</dependency>@RequiredArgsConstructor
@RestController
@RequestMapping("/http-client")
public class HttpClientChatController {
private final OkHttpClient client = new OkHttpClient().newBuilder()
.connectTimeout(10, TimeUnit.SECONDS)
.readTimeout(60, TimeUnit.SECONDS)
.writeTimeout(60, TimeUnit.SECONDS)
.build();
private final String modelName = "deepseek-r1:1.5b";
private final String apiHost = "http://127.0.0.1:11434/v1/chat/completions";
private final String apiKey = "ollama";
private final ObjectMapper objectMapper = new ObjectMapper();
@GetMapping(value = "/ai/generateStream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> chat(@RequestParam(value = "message", defaultValue = "你好") String message) throws IOException {
Map<String, Object> params = Map.of(
"model", modelName,
"messages", Collections.singletonList(Map.of("role", "user", "content", message)),
"stream", true
);
RequestBody requestBody = RequestBody.create(objectMapper.writeValueAsString(params), okhttp3.MediaType.parse("application/json; charset=utf-8"));
Request request = new Request.Builder()
.url(apiHost)
.header("Authorization", "Bearer " + apiKey)
.post(requestBody)
.build();
Call call = client.newCall(request);
return Flux.create(emitter -> {
try (Response response = call.execute()) {
BufferedSource source = response.body().source();
Buffer buffer = new Buffer();
while (source.read(buffer, 8192) != -1) {
String chunk = buffer.readUtf8Line();
if (chunk != null && !chunk.trim().isEmpty()) {
emitter.next(chunk);
}
}
} catch (IOException e) {
emitter.error(e);
} finally {
emitter.complete();
}
});
}
}流式返回:
LangChain4j
LangChain 是一个用于开发由语言模型驱动的应用程序的框架,提供了统一的 API 与一系列工具封装,大大简化了大模型应用开发。 官方提供了 Python 和 JS API,而 LangChain4j 是其 Java 版。
LangChain4j 抽象出了一个概念称为 AI Services,它封装了与大模型交互的一系列能力,并且可以基于我们声明的接口帮我们实现代理对象,注入相关能力,我们只需要该服务对象,就可以方便的与大模型交互。
对话大模型
目标
- SpringBoot 集成 LangChain4j,创建两个 AI Services,实现对话并流式返回:
- 接入 DeepSeek V3 API(因为本地 ollama 跑的有点弱),使用自动装配注入 deepSeekAssistant;
- 接入本地 Ollama 上运行的 R1,手动注入 ollamaAssistant;
- pom.xml
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
</dependency>
<!-- ollama 和 deepseek 都兼容 OpenAI API,所以引入此 starter -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
</dependency>
<!-- 支持流式输出的依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>1.0.0-beta2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>- application.yml
langchain4j:
# langchain4j-open-ai-spring-boot-starter 自动装配
open-ai:
chat-model:
base-url: https://api.deepseek.com/v1
api-key: ${DEEPSEEK_API_KEY}
model-name: deepseek-chat # 调用 v3
#model-name: deepseek-reasoner # 调用 R1
log-requests: true
log-responses: true
# 不是自动装配因为我们没有引入,langchain4j-ollama-spring-boot-starter
# 后面声明 Configuration 手动注入
ollama:
chat-model:
base-url: http://127.0.0.1:11434/v1
model-name: deepseek-r1:1.5b
log-requests: true
log-responses: trueconfig/MyAIConfiguration.java
@Configuration
@Slf4j
class MyAIConfiguration {
/**
* 监听日志
*/
@Bean
ChatModelListener chatModelListener() {
return new ChatModelListener() {
@Override
public void onRequest(ChatModelRequestContext requestContext) {
log.info("onRequest(): {}", requestContext.chatRequest());
}
@Override
public void onResponse(ChatModelResponseContext responseContext) {
log.info("onResponse(): {}", responseContext.chatResponse());
}
@Override
public void onError(ChatModelErrorContext errorContext) {
log.info("onError(): {}", errorContext.error().getMessage());
}
};
}
/**
* 注册一个流式返回的对象,用于注入给 DeepSeekAssistant
*/
@Bean
OpenAiStreamingChatModel openAiStreamingChatModel(@Autowired Environment env) {
return OpenAiStreamingChatModel.builder()
.baseUrl(env.getProperty("langchain4j.open-ai.chat-model.base-url"))
.apiKey(env.getProperty("DEEPSEEK_API_KEY"))
.modelName(env.getProperty("langchain4j.open-ai.chat-model.model-name"))
.logRequests(env.getProperty("langchain4j.open-ai.chat-model.log-requests", Boolean.class, false))
.logResponses(env.getProperty("langchain4j.open-ai.chat-model.log-responses", Boolean.class, false))
.build();
}
}config/OllamaAssistantConfiguration.java
@Configuration
public class OllamaAssistantConfiguration {
@Bean
ChatLanguageModel myOllamaChatModel(Environment env) {
return OpenAiChatModel.builder()
.baseUrl(env.getProperty("langchain4j.ollama.chat-model.base-url"))
.apiKey("ollama")
.modelName(env.getProperty("langchain4j.ollama.chat-model.model-name"))
.logRequests(env.getProperty("langchain4j.ollama.chat-model.log-requests", Boolean.class, false))
.logResponses(env.getProperty("langchain4j.ollama.chat-model.log-responses", Boolean.class, false))
.build();
}
@Bean
OpenAiStreamingChatModel myOllamaStreamingChatModel(Environment env) {
return OpenAiStreamingChatModel.builder()
.baseUrl(env.getProperty("langchain4j.ollama.chat-model.base-url"))
.apiKey("ollama")
.modelName(env.getProperty("langchain4j.ollama.chat-model.model-name"))
.logRequests(env.getProperty("langchain4j.ollama.chat-model.log-requests", Boolean.class, false))
.logResponses(env.getProperty("langchain4j.ollama.chat-model.log-responses", Boolean.class, false))
.build();
}
@Bean
OllamaAssistant ollamaAssistant(ChatLanguageModel myOllamaChatModel, OpenAiStreamingChatModel myOllamaStreamingChatModel) {
return AiServices.builder(OllamaAssistant.class)
.chatLanguageModel(myOllamaChatModel)
.streamingChatLanguageModel(myOllamaStreamingChatModel)
.build();
}
}service/DeepSeekAssistant.java
/**
* LangChain4j starter 将扫描类路径并找到所有使用 @AiService 注解的接口,使用应用程序上下文中可用的所有 LangChain4j 组件实现此接口,并将其注册为 bean。
* 如果引入多个 AI 服务,则必须显式指定 chatModel 名称。
*/
@AiService(wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", streamingChatModel = "openAiStreamingChatModel")
public interface DeepSeekAssistant {
@SystemMessage({"请记住你是“H公司”研发的智能助手,名字叫“V3”", "请简要回答用户提出的问题"})
String chat(String userMessage);
@SystemMessage({"请记住你是“H公司”研发的智能助手,名字叫“V3”", "请简要回答用户提出的问题"})
Flux<String> chatStream(String userMessage);
}service/OllamaAssistant.java
/**
* 由于我们调用 ollama 也通过 OpenAI API,而我们创建的 DeepSeekAssistant 已经绑定了自动装配,
* 所以这里我们不再使用 @AiService 注解,而是自定义一个 {@link OllamaAssistantConfiguration},
* 自行配置注入 OllamaAssistant
*/
public interface OllamaAssistant {
@SystemMessage({"请记住你是“Local公司”研发的智能助手,名字叫“R1”", "请简要回答用户提出的问题"})
String chat(String userMessage);
@SystemMessage({"请记住你是“Local公司”研发的智能助手,名字叫“R1”", "请简要回答用户提出的问题"})
Flux<String> chatStream(String userMessage);
}controller/ChatController.java
@RequiredArgsConstructor
@RestController
public class ChatController {
@Autowired
private DeepSeekAssistant deepSeekAssistant;
@Autowired
private OllamaAssistant ollamaAssistant;
@GetMapping("/ds/chat")
public String dsChat(@RequestParam(value = "message", defaultValue = "你是谁") String message) {
return deepSeekAssistant.chat(message);
}
@GetMapping(value = "/ds/chatStream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> dsChatStream(@RequestParam(value = "message", defaultValue = "你是谁") String message) {
return deepSeekAssistant.chatStream(message);
}
@GetMapping("/ollama/chat")
public String ollamaChat(@RequestParam(value = "message", defaultValue = "你是谁") String message) {
return ollamaAssistant.chat(message);
}
@GetMapping(value = "/ollama/chatStream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> ollamaChatStream(@RequestParam(value = "message", defaultValue = "你是谁") String message) {
return ollamaAssistant.chatStream(message);
}
}- 验证
会话记忆
手动维护和管理 ChatMessage 是繁琐的,因此 LangChain4j 提供了 ChatMemory 抽象以及若干开箱即用的实现。
注意会话历史和会话记忆是不同的。历史指用户在 UI 上看到的会话记录,需要我们程序自行管理维护;而会话记忆指在呈现给大模型的信息,并不一定等于历史输入输出的会话记录,例如可能会通过程序进行精简删除非必要信息以节省 token,或加入 Rag 检索返回的内容等。
// 注入一个 ChatMemoryProvider
@Bean
ChatMemoryProvider myChatMemoryProvider() {
return o -> MessageWindowChatMemory.withMaxMessages(10);
}
// 修改 DeepSeekAssistant.java
@AiService(wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", streamingChatModel = "openAiStreamingChatModel", chatMemoryProvider = "myChatMemoryProvider")
public interface DeepSeekAssistant {
// ...
// 添加一个带有 @MemoryId 的方法
String chat(@MemoryId int memoryId, @UserMessage String userMessage);
}
// 修改 Controller 方法,添加 memoryId 参数
@GetMapping("/ds/chat")
public String dsChat(@RequestParam(value = "message", defaultValue = "你是谁") String message, @RequestParam(value = "memoryId", required = false) String memoryId) {
return StringUtils.isBlank(memoryId) ? deepSeekAssistant.chat(message) : deepSeekAssistant.chat(memoryId, message);
}测试效果:
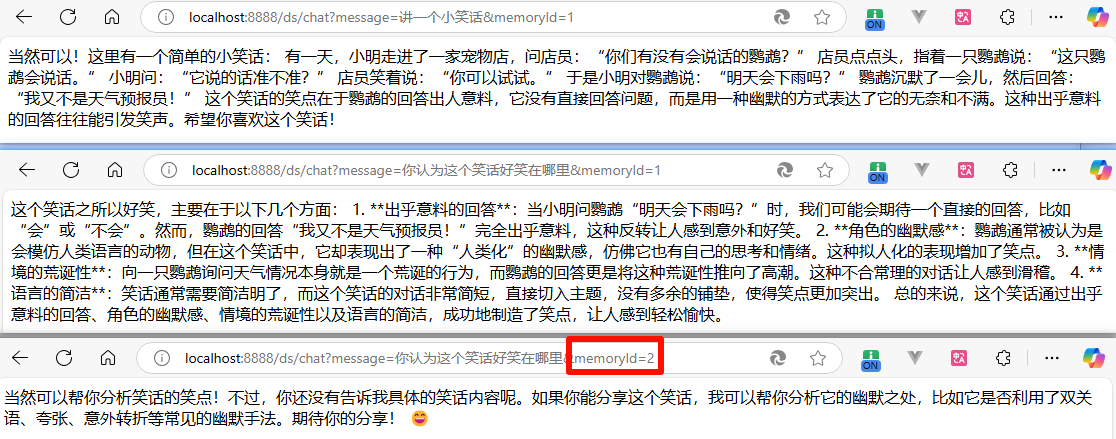
思考:如何持久化会话记忆?参考:langchain4j/langchain4j-examples
RAG Demo
使用 LangChain4j 内置的 easy rag 实现一个小的 demo.
- pom.xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
</dependency>- 代码
// 注入 EmbeddingStoreContentRetriever Bean
@Bean
EmbeddingStoreContentRetriever myContentRetriever() throws URISyntaxException {
URI uri = this.getClass().getClassLoader().getResource("testRag.txt").toURI();
Document document = FileSystemDocumentLoader.loadDocument(Path.of(uri));
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor.ingest(document, embeddingStore);
return EmbeddingStoreContentRetriever.from(embeddingStore);
}
// 修改 DeepSeekAssistant.java 中的注解,添加 contentRetriever 属性
@AiService(wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", streamingChatModel = "openAiStreamingChatModel",
chatMemoryProvider = "myChatMemoryProvider", contentRetriever = "myContentRetriever"
)
public interface DeepSeekAssistant {...}- testRag.txt 内容如下:
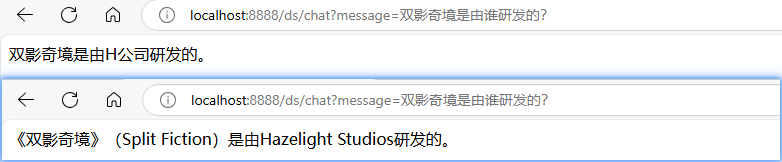
《双影奇境》(Split Fiction)是由Hazelight Studios研发,Electronic Arts(EA)发行的一款双人合作冒险游戏,于2025年3月7日在中国大陆发售登陆PS5、Xbox以及PC平台。
《双影奇境》中,玩家将结识两位风格迥异的作家——米欧和佐伊。她们被骗进入一台意在窃取创意的机器后,陷入了自己创作的故事之中。她们必须相互依靠,努力掌握各种技能重新回到现实。
2025年2月21日,《双影奇境》的好友通行证宣传片公开。 3月7日,《双影奇境》正式发售。截至2025年3月11日,《双影奇境》在发售2天内销量突破100万份。对比使用 Rag 前后的回答效果:
Function Call
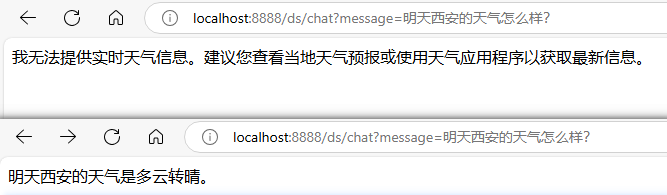
需求:实现“提问明天西安天气怎么样?”,大模型需要调用两个工具,一个用于获取日期,一个用于获取天气。
注意:DeepSeek R1 的思考链会导致判断方法调用异常,所以建议使用 V3 测试。
- 新建一个工具类
MyToolBox.java,并使用@tool、@P注解提供提示词
@Component
public class MyToolBox {
private static final DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
@Tool("获取当前时间。如果用户提问的问题涉及了日期时间,则可以调用该工具获取与计算。例如当用户问“明天xxx怎么样”,则可以调用该方法获取当前时间,再加一天得到明天的日期")
public String getNowTime(@ToolMemoryId String memoryId) {
return dateTimeFormatter.format(LocalDateTime.now());
}
@Tool("查询指定日期、指定地点的天气")
public Map<String, String> getWeather(
@ToolMemoryId String memoryId,
@P("yyyy-MM-dd 格式的日期,代表要查询的日期") String date,
@P("要查询的地点,是一个地名") String location
) {
return Map.of(
"地点", location,
"日期", date,
"查询结果", "多云转晴"
);
}
}- 修改
DeepSeekAssistant接口注解,添加tools属性
@AiService(...
tools = {"myToolBox"}
...
)
public interface DeepSeekAssistant {...}对比回答结果:
调用 MCP Server
首先需要一个 MCP Server,直接在 Model Context Protocol Servers 找一个开源的试试,例如 Filesystem MCP Server 是一个基于 Node.js 实现的 MCP Server,可用于操作文件系统,实现读写、移动文件等操作。
# 全局安装
npm install -g @modelcontextprotocol/server-filesystem
# 启动命令测试
npx -y @modelcontextprotocol/server-filesystem [...可操作的目录]
# 例如
npx -y @modelcontextprotocol/server-filesystem C:/Users/henry/Desktop
# 输出以下表示成功,然后关了即可,因为我们要从程序中启动
Secure MCP Filesystem Server running on stdio
Allowed directories: [ 'C:\\Users\\henry\\Desktop' ]- pom.xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-mcp</artifactId>
</dependency>- 新增一个
service/DeepSeekAssistantForMcp.java.
public interface DeepSeekAssistantForMcp {
String chat(String userMessage);
Flux<String> chatStream(String userMessage);
}- 新增一个
config/McpConfiguration.java- 注意代码中的启动命令使用了绝对路径,否则可能找不到命令,并且将 npx 替换为了 node 命令
@Configuration
public class McpConfiguration {
@Bean
McpTransport transport() {
return new StdioMcpTransport.Builder()
.command(
List.of(
"C:/DevKit/nodejs/fnm/node-versions/v20.19.0/installation/node.exe",
"C:/DevKit/nodejs/node_global/node_modules/@modelcontextprotocol/server-filesystem/dist/index.js",
"C:/Users/henry/Desktop"
)
)
.logEvents(true)
.build();
}
@Bean
McpClient mcpClient(McpTransport transport) {
return new DefaultMcpClient.Builder()
.transport(transport)
.build();
}
@Bean
ToolProvider mcpToolProvider(McpClient mcpClient) {
return McpToolProvider.builder()
.mcpClients(List.of(mcpClient))
.build();
}
@Bean
DeepSeekAssistantForMcp mcpChatAssistant(OpenAiChatModel openAiChatModel, ChatMemoryProvider myChatMemoryProvider, ToolProvider mcpToolProvider) {
return AiServices.builder(DeepSeekAssistantForMcp.class)
.chatLanguageModel(openAiChatModel)
.chatMemoryProvider(myChatMemoryProvider)
.toolProvider(mcpToolProvider)
.build();
}
}- 修改
ChatController.java添加测试接口
//...
@Autowired
private McpClient mcpClient;
@Autowired
private DeepSeekAssistantForMcp mcpChatAssistant;
@GetMapping("/ds/chat-mcp")
public String dsChatMcp(@RequestParam(value = "message", defaultValue = "你是谁") String message) {
// 打印可用的 tools 信息
mcpClient.listTools().forEach(toolSpecification -> log.info(toolSpecification.toString()));
return mcpChatAssistant.chat(message);
}
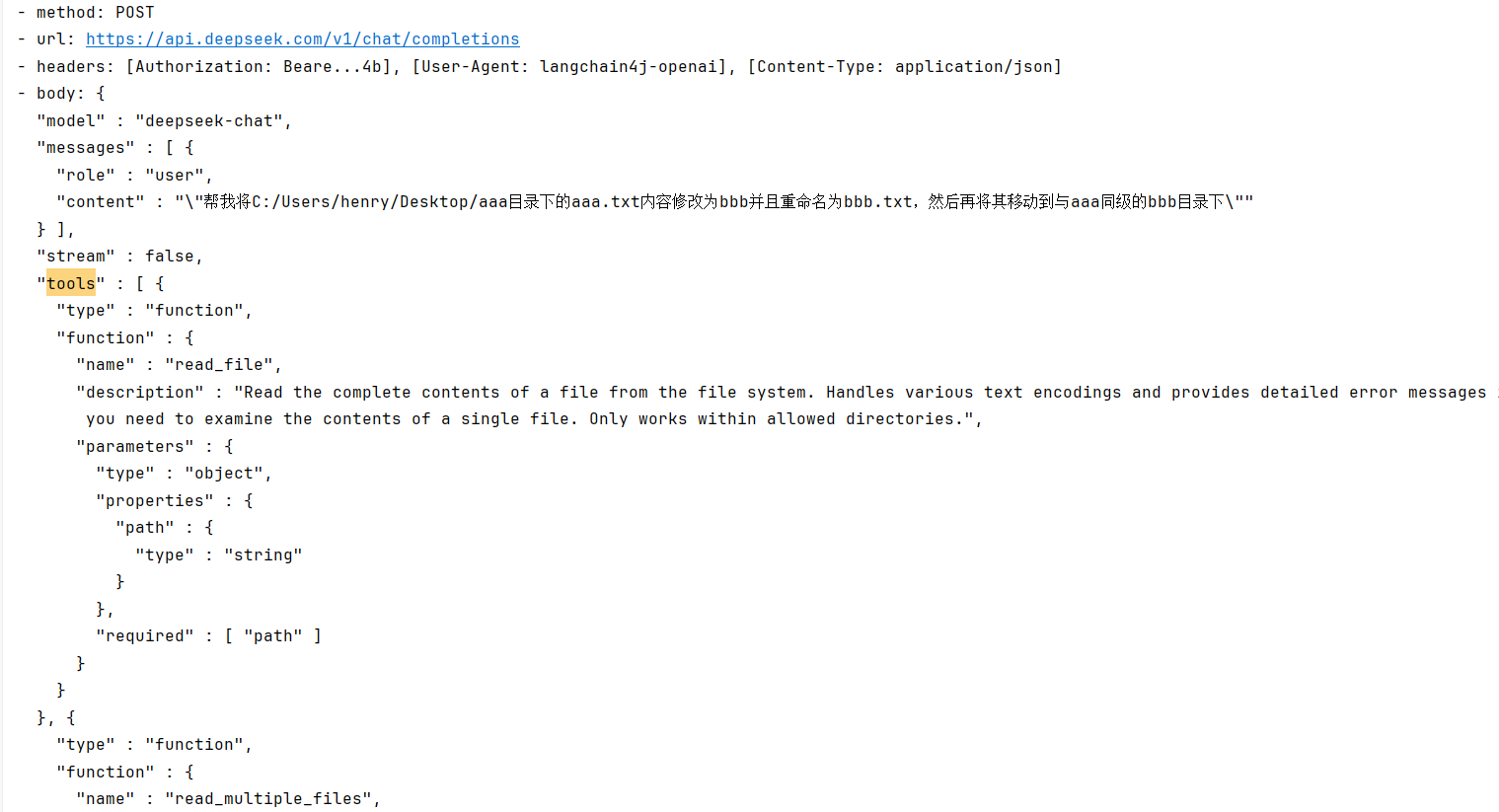
//...测试调用该接口:在桌面上创建两个文件夹 aaa 和 bbb,在 aaa 中创建一个文本文件 aaa.txt 内容为 aaa,提问 "帮我将C:/Users/henry/Desktop/aaa目录下的aaa.txt内容修改为bbb并且重命名为bbb.txt,然后再将其移动到与aaa同级的bbb目录下"。

可以看到后台请求会自动带上该 MCP Server 的 Tools 列表。
其他待探索
多个 AI Services 编排、结构化输出、多模态相关、Agent MCP Server 开发…