Overview
操作系统线程调度
JVM内存模型与锁优化
Java多线程-基础
常用的几个辅助类
CountDownLatch
门闩,适用于一个或多个线程需要等待其他 N 个线程的情况,它是一次性的,不能被重置。
@Test
public void testCountDownLatch() throws InterruptedException {
CountDownLatch latch = new CountDownLatch(5);
for (int i = 0; i < 5; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName());
latch.countDown();
}, "t" + i).start();
}
System.out.println("before await");
// latch 没有归零则一直阻塞
latch.await();
System.out.println("after await");
}CyclicBarrier
屏障,当有指定个数的线程都到达屏障后,才可以一同继续前行,否则先到的线程被阻塞。与 CountDownLatch 相比,它默认可以循环多次使用、也可以手动重置。
@Test
public void testCyclicBarrier() {
// 可以循环使用,可以传递一个 Runnable,当屏障满足条件后,会异步执行
CyclicBarrier barrier = new CyclicBarrier(5, ()->{
System.out.println("屏障满足条件了。");
});
// 此处声明循环 10 次,屏障会满足两次
for (int i = 0; i < 10; i++) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "--before");
try {
barrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + "--after");
}, "t" + i).start();
}
}Phaser
Phaser(相位器) 类似 CyclicBarrier 但使用起来更加灵活,可以随时通过 register(注册) 或注销 (deregister) 来增减屏障数量。注册在同一个 phaser(屏障) 上的 party(参与的线程) 数目可能会随着时间而变化。
Phaser 可以反复使用,它拥有一个 phase number (阶段号),每当屏障条件满足时,阶段号自增,直到达到 Integer.MAX_VALUE 后归零。可以重写屏障满足条件时执行的方法 onAdvance。
/*
* 例子:服务员(main线程)上菜,
* 分三个阶段:0饮品、1正餐、3甜点
* 要求每个阶段的菜上齐后,客人才可以开吃
* */
@Test
public void TestPhaser() throws InterruptedException {
// 参数 1 表示注册 main 线程自己(parties+1)
Phaser phaser = new Phaser(1) {
@Override
protected boolean onAdvance(int phase, int registeredParties) {
if (phase == 0) {
System.out.println("饮品上齐了!");
} else if (phase == 1) {
System.out.println("正餐上齐了!");
} else if (phase == 2) {
System.out.println("甜点上齐了!");
} else {
System.out.println("未知的阶段");
}
// 返回 true 会终止 phaser,后续 await 操作将不再阻塞在 phaser 上
return false;
}
};
for (int i = 1; i <= 5; i++) {
// 动态注册 +1
phaser.register();
new Thread(() -> {
Stream.of("饮品", "正餐", "甜点")
.forEach(item -> {
// 等菜上齐(阻塞)
phaser.arriveAndAwaitAdvance();
System.out.println(Thread.currentThread().getName() + "-吃-" + item);
});
}, "客人" + i).start();
}
// 第 0 阶段,arrive 到达屏障但不阻塞
phaser.arrive();
Thread.sleep(500);
// 第 1 阶段
phaser.arrive();
Thread.sleep(500);
// 第 2 阶段,main 线程工作完成,注销自己(parties-1)
phaser.arriveAndDeregister();
}Semaphore
信号量,可以指定初始许可数量、每次申请和释放的许可数量。注意重复执行 release() 时,许可会累加,不会受到初始许可数的限制。
@Test
public void testSemaphore() throws InterruptedException {
// 初始化许可数量,可以指定是否公平
Semaphore semaphore = new Semaphore(0, false);
// release 会累加许可数量,并且不受初始化许可数量限制
semaphore.release(3);
for (int i = 0; i < 10; i++) {
new Thread(() -> {
try {
// 申请许可
semaphore.acquire(2);
System.out.println(Thread.currentThread().getName() + "获得许可");
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
// 释放许可
semaphore.release(2);
}
}).start();
}
Thread.sleep(3000);
}LockSupport
Java 封装的接近底层的同步原语,调用 UNSAFE 类的 native 方法,很多锁与同步类的实现都用到了它,不建议直接使用。
对于使用它的每个线程,LockSupport 类似于有且只有一个许可的 Semaphore;park() 和 unPark() 方法方法执行顺序可以颠倒,但多次执行 unPark() 的效果和执行一次相同,因为只有一个许可。
park 状态的线程将不再参与调度,直到被唤醒,减少了轮询导致的忙等待。当 park 状态的线程被 interrupt 时,会立即被唤醒,不会抛出异常。被唤醒的线程需要在循环中判断是继续执行还是重新 park,因为可能被虚假唤醒。
// 打印 a1b2c3
@Test
public void testLockSupport() {
Thread t1;
Thread t2 = Thread.currentThread();
List<String> list = Arrays.asList("a", "b", "c");
t1 = new Thread(() -> {
for (int i = 1; i <= list.size(); i++) {
LockSupport.park();
System.out.print(i);
LockSupport.unpark(t2);
}
}, "t1");
t1.start();
list.forEach(item -> {
System.out.print(item);
LockSupport.unpark(t1);
LockSupport.park();
});
}ReentrantReadWriteLock
读读不互斥、读写/写写互斥,当一个线程先获得写锁,再申请读锁时,降级为写锁。如果采取默认的非公平策略,那么当读多写少时,可能会有写饥饿。
@Test
public void testReentrantReadWriteLock() throws InterruptedException {
ReentrantReadWriteLock rwLock = new ReentrantReadWriteLock(false);
ReentrantReadWriteLock.ReadLock readLock = rwLock.readLock();
ReentrantReadWriteLock.WriteLock writeLock = rwLock.writeLock();
for (int i = 0; i < 100; i++) {
new Thread(() -> {
try {
TimeUnit.MILLISECONDS.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
readLock.lock();
System.out.println(Thread.currentThread().getName() + ":" + this.intField);
readLock.unlock();
}, "read" + i).start();
}
new Thread(() -> {
writeLock.lock();
this.intField++;
System.out.println("write:" + this.intField);
writeLock.unlock();
}, "write").start();
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}StampedLock
StampedLock 在读写锁的基础上,新增了乐观读,允许乐观读时其他线程获得写锁,从而解决了 ReentrantReadWriteLock 的写饥饿问题。乐观读中需要校验邮戳,如果校验失败则需要升级为悲观读重新读。
注意:StampedLock 是不可重入的,其悲观读写锁都不支持 Condition。
public class Test07StampLock {
private double x, y;
private final StampedLock sl = new StampedLock();
// 移动坐标
void move(double deltaX, double deltaY) {
long stamp = sl.writeLock();
try {
x += deltaX;
y += deltaY;
} finally {
sl.unlockWrite(stamp);
}
}
// 计算到原点的距离
double distanceFromOrigin() {
// 先乐观读,返回 0 表示当前写锁被占了
long stamp = sl.tryOptimisticRead();
try {
// 假设读取耗时
Thread.sleep(1);
for (; ; stamp = sl.readLock()) {
// 如果写锁被占了,升级为悲观读锁
if (stamp == 0L) {
System.out.println("写锁被占了,将升级为悲观读锁");
continue;
}
double currentX = x;
double currentY = y;
// 如果校验不通过,则也升级为悲观读锁
if (!sl.validate(stamp)) {
System.out.println("校验不通过,将升级为悲观读锁");
continue;
}
return Math.hypot(currentX, currentY);
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
if (sl.isReadLocked()) sl.unlockRead(stamp);
}
}
@Test
public void testStampLock() throws InterruptedException {
Test07StampLock stampLock = new Test07StampLock();
for (int i = 0; i < 100; i++) {
new Thread(() -> {
System.out.println(stampLock.distanceFromOrigin());
}, "t" + i).start();
}
new Thread(() -> {
stampLock.move(3, 4);
}, "write").start();
Thread.sleep(0, 1);
new Thread(() -> {
stampLock.move(1, 2);
}, "write").start();
Thread.sleep(3000);
}
}Exchanger
exchanger 是一个交换点,用于两个线程之间交换数据,当两个线程都到达交换点后,调用 exchange 方法,交换彼此的数据。下面的例子是,两个线程,一个从 0 自增 100,一个从 100 自减到 0,然后交换数据。
@Test
public void testExhanger() {
Exchanger<Integer> exchanger = new Exchanger<>();
new Thread(() -> {
int increment = 0;
while (true) {
increment++;
if (increment == 100) {
try {
System.out.println(Thread.currentThread().getName() + "交换前:" + increment);
increment = exchanger.exchange(increment);
System.out.println(Thread.currentThread().getName() + "交换后:" + increment);
return;
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}, "increment").start();
new Thread(() -> {
int decrement = 100;
while (true) {
decrement--;
if (decrement == 0) {
try {
System.out.println(Thread.currentThread().getName() + "交换前:" + decrement);
decrement = exchanger.exchange(decrement);
System.out.println(Thread.currentThread().getName() + "交换后:" + decrement);
return;
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}, "decrement").start();
}阻塞队列
- BlockingQueue
- ArrayBlockingQueue
- LinkedBlockingQueue
- …
当队列满/空时:调用 add/remove 方法时会抛出异常;调用 offer 方法返回 true/false,调用 poll/peek 方法返回 element/null;调用 put/take 方法则一直阻塞。
| 方法 | 抛异常 | 返回特殊值 | 阻塞 |
|---|---|---|---|
| 添加 | add(e) | offer(e, time, unit) | put(e) |
| 弹出 | remove() | poll(time, unit) | take() |
| 查看队首 | element() | peek() | / |
创建线程池
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)- corePoolSize:核心线程数量
- maximumPoolSize:最大线程数量
- keepAliveTime:(最大数 - 核心数) 个线程的存活时间
- unit:keepAliveTime 的单位
- workQueue:任务阻塞队列
- threadFactory:线程工厂
- handler:拒绝策略
- AbortPolicy:默认策略,直接抛出异常
- CallerRunsPolicy:提交者执行 (可以降低新任务的提交速度)
- DiscardOldestPolicy:丢弃队列中等待最久的任务
- DiscardPolicy:静默丢弃任务
任务提交方式
提交任务方式:submit vs execute
| 特性 | executor.execute(Runnable command) | executor.submit(Callable<T> task) / executor.submit(Runnable task) |
|---|---|---|
| 返回值 | void (无返回值) | Future<T> (有返回值) |
| 异常处理 | 任务内部异常不会传播到调用者线程,需要在任务内部 try-catch 处理 | 任务内部异常会被包装在 ExecutionException 中,当调用 future.get() 时抛出,便于调用者处理 |
| 适用任务 | 只需执行,不关心结果或异常的 Runnable 任务 | 需要获取执行结果或需要处理异常的 Callable 或 Runnable 任务 |
| 任务类型 | 只能提交 Runnable | 可以提交 Runnable 或 Callable |
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.execute(() -> {throw new RuntimeException("execute");}); // JVM UncaughtExceptionHandler 处理,即打印 System.err
Future<Object> future = executor.submit(() -> {throw new RuntimeException("submit");}); // FutureTask 捕获封装为 ExecutionException,如果不 get 则静默处理
try {
future.get();
} catch (Exception e) {
throw new RuntimeException(e);
}线程池实现生产者消费者
public static void main(String[] args) {
AtomicInteger threadNumber = new AtomicInteger(1);
ThreadPoolExecutor executor = null;
try {
// 创建线程池,队列大小设为线程数的 1.5 倍
executor = new ThreadPoolExecutor(
5, 5, 5, TimeUnit.SECONDS,
new LinkedBlockingQueue<>((int) (5 * 1.5)),
r -> new Thread(r, "custom-prefix-" + threadNumber.getAndIncrement()),
new BlockingPolicy(10, TimeUnit.MINUTES)
);
// 主线程提交任务
do {
executor.execute(new MyTask(xxx, xxx));
} while (xxx);
// 主线程阻塞
executor.shutdown(); // 有序关闭,不再接受新任务,但会完成已提交的任务
if (!executor.awaitTermination(1, TimeUnit.DAYS)) {
// 如果超时,说明还有任务未完成
log.warn("线程池在指定时间内未能完全关闭,可能有任务仍在执行。");
// 可以选择强制关闭
List<Runnable> unfinishedTasks = executor.shutdownNow();
log.warn("强制关闭线程池,未完成的任务数量: {}", unfinishedTasks.size());
}
} catch (Throwable e) {
if (e instanceof InterruptedException) {
log.info("任务被终止...");
} else {
log.error("任务执行出错", e);
}
} finally {
if (executor != null) {
executor.shutdownNow();
}
}
}
/**
* 要执行的任务逻辑
*/
private static class MyTask implements Runnable {
// 批次号
private Integer batchNo;
// 要消费的数据
private List<Object> dataList;
public MyTask(Integer batchNo, List<Object> dataList) {
this.batchNo = batchNo;
this.dataList = dataList;
}
@Override
public void run() {
// do sth.
}
}
/**
* 自定义一个阻塞策略
*/
private static class BlockingPolicy implements RejectedExecutionHandler {
private final long waitTime;
private final TimeUnit unit;
public BlockingPolicy(long waitTime, TimeUnit unit) {
this.waitTime = waitTime;
this.unit = unit;
}
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
if (!executor.isShutdown()) {
try {
// 尝试将任务放入队列,如果队列满了,则阻塞等待
if (!executor.getQueue().offer(r, waitTime, unit)) {
// 如果等待超时,任务仍然无法放入队列,则抛出异常
throw new RejectedExecutionException("Task " + r + " rejected from " + executor + " after waiting for " + waitTime);
}
} catch (InterruptedException e) {
// 恢复中断状态
Thread.currentThread().interrupt();
throw new RejectedExecutionException("Task " + r + " rejected because the current thread was interrupted", e);
}
}
}
}Fork/Join
JDK1.7 引入的将大任务拆分为很多个小的子任务、异步执行再合并为最终结果的工具类。适用于那些可以通过分治算法解决的任务。
- 任务对象 ForkJoinTask 的常用子类:
- RecursiveTask:Fork/Join 框架中的一个基类,表示有返回值的任务
- RecursiveAction:表示无返回值的任务
- CountedCompleter:任务完成后执行回调
fork()方法用于异步地安排一个任务执行,而join()方法则等待任务完成并获取其结果- 执行任务的线程:ForkJoinWorkerThread
- 线程池:ForkJoinPool 特点是通过工作窃取算法来优化任务分配和执行效率,当一个线程完成了自己的任务后,它可以“窃取”其他线程的任务来执行,从而减少线程等待时间,提高资源利用率。
代码示例:
public class CustomForkJoinPoolExample {
public static void main(String[] args) {
// 自定义并行度为4的ForkJoinPool
ForkJoinPool customPool = new ForkJoinPool(4);
// 创建任务
MyRecursiveTask task = new MyRecursiveTask(0, 1000);
// 在自定义的ForkJoinPool中执行任务
long result = customPool.invoke(task);
System.out.println("Result: " + result);
// 关闭线程池
customPool.shutdown();
}
// 示例任务类
static class MyRecursiveTask extends RecursiveTask<Long> {
private final int start;
private final int end;
MyRecursiveTask(int start, int end) {
this.start = start;
this.end = end;
}
// 任务的核心方法,定义了如何分割任务以及如何合并结果。
@Override
protected Long compute() {
if (end - start <= 10) { // 小任务直接计算
return calculateSum(start, end);
} else {
// 分割任务
int middle = (start + end) / 2;
MyRecursiveTask leftTask = new MyRecursiveTask(start, middle);
MyRecursiveTask rightTask = new MyRecursiveTask(middle + 1, end);
leftTask.fork(); // 异步执行左侧任务
Long rightResult = rightTask.compute(); // 同步执行右侧任务
Long leftResult = leftTask.join(); // 等待左侧任务完成
return leftResult + rightResult;
}
}
// 求和 [a,b]
private long calculateSum(int start, int end) {
long sum = 0;
for (int i = start; i <= end; i++) {
sum += i;
}
return sum;
}
}
}CompletableFuture
小结
FutureTask ,只能阻塞或轮询:
@Test
public void testFutureTask() throws ExecutionException, InterruptedException {
FutureTask<String> task = new FutureTask<>(() -> "futureTask");
new Thread(task).start();
// 轮询
while (!task.isDone()) {
System.out.println("ing...");
}
// 阻塞
System.out.println(task.get());
}CompletableFuture 是 FutureTask 的加强版,增加了异步回调方法的注册,减少阻塞和轮询。常用 API 小结:
任务提交
- runAsync():无返回值
- supplyAsync():有返回值
获取结果
- get():获取值,会抛出 Interrupted 异常;
- get(time, unit):同上;
- join():获取值,不会抛出 Interrupted 异常;
- getNow(defaultValue):如果当前没有执行完,返回默认值;
- complete(defaultValue):返回 Boolean 表示当前调用是否将 cf 状态置为了完成 ,即调用时 cf 未执行完成,此操作强制标记为完成,并返回 true,后续的 join/get 会立即返回 defaultValue ;
流程控制,串联执行
- thenApply(fun):接收上一步的结果,进一步处理,有返回值,如果某一步发生异常,则终止,执行异常处理逻辑;
- handle(biFun<v,e>):接收上一步的结果与异常;
- thenAccept(consumer):消费上一步的结果,返回 Void;
- thenRun() vs thenRunAsync():两者都是在上一个任务执行完后执行,且不依赖于上一个任务的返回结果。两者的区别在于当传递自定义线程池时,第一个任务后,thenRun 仍会使用自定义线程池,而 thenRunAsync 如果不指定会使用 ForkJoinPool;
- whenComplete(v, e):接收上一步的结果与异常,与 handle 的不同在于 whenComplete 如果接收到了异常 e,则会隐藏本身 stage 执行时产生的异常,只把接收到的 e 传递到后面的 stage;
任务合并,并行执行
- thenCombine(cf, fun):合并两个 cf 的结果,返回新的结果;
- allOf(…cf):所有任务完成后,返回一个新的 cf,企图通过这个 cf 获取值将得到 null;
- anyOf(…cf):返回最快执行完的 cf,即使他发生了异常;
异常处理
- exceptionally(e):注意只能捕获上一步任务中的异常;
结合 Stream 流
public static void main(String[] args) {
AtomicInteger threadNumber = new AtomicInteger(1);
ExecutorService executor = new ThreadPoolExecutor(
5, 5, 5, TimeUnit.SECONDS,
new LinkedBlockingQueue<>((int) (5 * 1.5)),
r -> new Thread(r, "custom-prefix-" + threadNumber.getAndIncrement()),
new ThreadPoolExecutor.CallerRunsPolicy());
List<Integer> dataList = Arrays.asList(1, 2, 3, 4, 5);
List<CompletableFuture<Integer>> futures = dataList.stream()
.map(data -> CompletableFuture.supplyAsync(() -> {
// do sth.
return data;
}, executor))
.collect(Collectors.toList());
// 主线程阻塞
CompletableFuture<Void> allFutures = CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]));
allFutures.join();
// do sth.
}测试 demo
complete
@Test
public void testCfComplete() throws ExecutionException, InterruptedException {
CompletableFuture<String> cf = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return "cf-task";
});
Thread.sleep(200); // 对比有无此行的输出结果
boolean complete = cf.complete("complete");
System.out.println(complete);
System.out.println(cf.join());
System.out.println(cf.get());
}thenApply & handle & thenAccept
@Test
public void testCfApplyHandleAccept() {
CompletableFuture
.supplyAsync(() -> 1)
// 发生异常
.thenApply(v -> v /= 0)
.exceptionally(throwable -> {
// 打印 ArithmeticException
System.out.println(throwable.getLocalizedMessage());
return 0;
})
.handle((v, e) -> {
System.out.println(v);
// 此处的 e == null,因为已经被上一个 exceptionally 处理
System.out.println(e.getLocalizedMessage());
return 100;
})
.exceptionally(throwable -> {
// 打印 NPE,因为上一步 handle 中 e == null
System.out.println(throwable.getLocalizedMessage());
return 0;
})
// 消费,无返回值
.thenAccept(System.out::println)
.join();
}thenRun & thenRunAsync
@Test
public void testCfRunAndRunAsync() {
ExecutorService pool = Executors.newFixedThreadPool(3);
CompletableFuture
.runAsync(() -> {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + "---initRun");
}, pool)
.thenRun(() -> {
System.out.println(Thread.currentThread().getName() + "---thenRun");
})
.thenRunAsync(() -> {
System.out.println(Thread.currentThread().getName() + "---thenRunAsync");
}, pool) // 对于 thenRunAsync,此处不指定 pool,则会使用 ForkJoinPool
.join();
}thenCombine & allOf & anyOf
@Test
public void testCfCombine() {
CompletableFuture<Integer> initCf = CompletableFuture
.supplyAsync(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + "---initCf");
return 1;
});
CompletableFuture<Integer> combineCf = CompletableFuture
.supplyAsync(() -> {
System.out.println(Thread.currentThread().getName() + "---combineCf");
return 1;
});
CompletableFuture<Integer> result1 = initCf.thenCombine(combineCf, Integer::sum);
CompletableFuture<Integer> result2 = combineCf.thenCombine(initCf, Integer::sum);
System.out.println(result1.join());
System.out.println(result2.join());
}@Test
public void testAllOfAndAnyOf() {
CompletableFuture cf1 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return "cf1";
});
CompletableFuture cf2 = CompletableFuture.supplyAsync(() -> {
int a = 1 / 0;
return "cf2";
});
CompletableFuture anyCf = CompletableFuture
.anyOf(cf1, cf2)
// 对于 anyOf,第一个完成的 cf 报错,anyCf 才会报错
.exceptionally(e -> {
System.out.println(e.getLocalizedMessage());
return "anyCf-exception";
});
System.out.println(anyCf.join()); // cf1 或 null(cf2报错导致)
CompletableFuture allCf = CompletableFuture
.allOf(cf1, cf2)
// 对于 allOf,任意一个 cf 报错,allOf 都会报错
.exceptionally(e -> {
System.out.println(e.getLocalizedMessage());
System.out.println("allCf-exception");
return null;
});
// 企图使用 allCf 获取所有结果,但是为 null
System.out.println(allCf.join()); // null
// 应该使用 cf1、cf2 获取各自的结果
System.out.println(cf1.join()); // cf1
// cf2 没有异常处理,所以此处会报错
System.out.println(cf2.join()); // 报错
}exceptionally & whenComplete
@Test
public void testExceptionallyAndWhenComplete() {
CompletableFuture cf = CompletableFuture
.supplyAsync(() -> {
int a = 1 / 0;
return null;
})
.whenComplete((v, e) -> {
if (e != null) {
System.out.println("whenComplete---" + e.getLocalizedMessage());
System.out.println(System.identityHashCode(e));
}
throw new RuntimeException("whenComplete-throw");
})
/*
* whenComplete 与 handle 不同在于:
* 如果 whenComplete 接收到的 e != null,则此处的 exceptionally 接收到的 e 与 whenComplete 中的 e 相同;
* 否则,exceptionally 才能接收到 whenComplete 本身执行逻辑中产生的异常
* */
.exceptionally(e -> {
System.out.println(System.identityHashCode(e));
System.out.println("e2---" + e.getLocalizedMessage());
return "e2";
});
System.out.println(cf.join());
}原子类
大多基于 cas 的乐观锁 (无锁) 思想,底层使用 cpu 的 cmpxchg 指令保证操作的原子性,多核 cpu 时会锁总线。
基本类型
- AtomicInteger
- AtomicLong
- AtomicBoolean
| API | 说明 |
|---|---|
| get() | 获取当前值 |
| getAndSet(int newValue) | 获取当前值,并设置新值 |
| getAndIncrement() | 获取当前值,并自增 |
| getAndDecrement() | 获取当前值,并自减 |
| getAndAdd(int delta) | 获取当前值,并增加 delta |
| compareAndSet(expectValue, newValue) | cas 设置新值 |
数组类型
- AtomicIntegerArray
- AtomicLongArray
- AtomicReferenceArray
与基本类型类似,不过是对应的方法中接收数组下标作为参数。
@Test
public void testAtomicIntegerArray() {
AtomicIntegerArray array = new AtomicIntegerArray(new int[]{0, 1, 2});
array.getAndIncrement(0);
array.getAndSet(1, 2);
System.out.println(array);
}原子引用
- AtomicReference:存在 ABA 问题;
- AtomicStampedReference:带版本号,解决 ABA 问题;
- AtomicMarkableReference:带 Boolean 类型的标志位,一旦修改就会修改标志位为 true;
@AllArgsConstructor
@Data
@EqualsAndHashCode
static class Person {
private String name;
private int age;
}
@Test
public void testAtomicReference() {
Person p1 = new Person("zhangsan", 18);
Person p2 = new Person("zhangsan", 18);
Person p3 = new Person("lisi", 20);
System.out.println(p1.equals(p2));
System.out.println(System.identityHashCode(p1) == System.identityHashCode(p2));
AtomicReference<Person> ar = new AtomicReference<>(p1);
// cas 通过内存地址比较,而不是 equals
boolean b = ar.compareAndSet(p2, p3);
System.out.println(b);
}
@Test
public void testAtomicStampedReference() throws InterruptedException {
Person p1 = new Person("zhangsan", 18);
Person p2 = new Person("lisi", 19);
Person p3 = new Person("wangwu", 20);
AtomicStampedReference<Person> reference = new AtomicStampedReference<>(p1, 0);
new Thread(() -> {
int expectedStamp = reference.getStamp();
int newStamp = expectedStamp + 1;
// 睡一会保证 t2 拿到的 stamp 与 t1 相同
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
reference.compareAndSet(p1, p2, expectedStamp, newStamp);
System.out.println(Thread.currentThread().getName() + ":" + reference.getReference());
}, "t1").start();
new Thread(() -> {
int expectedStamp = reference.getStamp();
int newStamp = expectedStamp + 1;
reference.compareAndSet(p1, p3, expectedStamp, newStamp);
System.out.println(Thread.currentThread().getName() + ":" + reference.getReference());
}, "t2").start();
Thread.sleep(1000);
}对象属性更新
使用反射原子性修改对象的非 static 非 final 属性值,属性必须被 volatile 修饰,对于访问修饰符,必须能够通过 . 直接访问到。
- AtomicIntegerFieldUpdater:只能修改 int,不能修改 Integer
- AtomicLongFieldUpdater:只能修改 long,不能修改 Long
- AtomicReferenceFieldUpdater
使用时需要调用 newUpdater() 创建一个更新器:
@Data
@EqualsAndHashCode
static class MyClass {
private volatile int intA;
public volatile int intB;
protected volatile int intC;
public volatile Integer integerA = 0;
}
@Test
public void testAtomicFieldUpdater() {
MyClass mc = new MyClass();
System.out.println(mc);
/*// 不能修改 private
AtomicIntegerFieldUpdater<MyClass> intAUpdater = AtomicIntegerFieldUpdater.newUpdater(MyClass.class, "intA");
System.out.println(intAUpdater.addAndGet(mc, 1));*/
AtomicIntegerFieldUpdater<MyClass> intBUpdater = AtomicIntegerFieldUpdater.newUpdater(MyClass.class, "intB");
System.out.println(intBUpdater.addAndGet(mc, 1));
AtomicIntegerFieldUpdater<MyClass> intCUpdater = AtomicIntegerFieldUpdater.newUpdater(MyClass.class, "intC");
System.out.println(intCUpdater.addAndGet(mc, 1));
/*// 不能修改包装类
AtomicIntegerFieldUpdater<MyClass> integerAUpdater = AtomicIntegerFieldUpdater.newUpdater(MyClass.class, "integerA");
System.out.println(integerAUpdater.addAndGet(mc, 1));*/
AtomicReferenceFieldUpdater<MyClass, Integer> rUpdater =
AtomicReferenceFieldUpdater.newUpdater(MyClass.class, Integer.class, "integerA");
System.out.println(rUpdater.compareAndSet(mc, 0, 10));
System.out.println(mc.getIntegerA());
}其他
LongAdder 在高争用的情况下,性能要优于 AtomicLong,代价是额外的空间开销。
- LongAdder:只能从 0 开始,可以调用 add(delta) 指定步长;
- LongAccumulator:可以扩展自定义操作;
- DoubleAccumulator
- DoubleAdder
@Test
public void testLongAdder() {
LongAdder adder = new LongAdder();
// 创建 10 个线程,每个累加 10000 次
List<CompletableFuture<Void>> cfList1 =
Stream.of(new Integer[10])
.map(item -> CompletableFuture.runAsync(
() -> {
for (int i = 0; i < 10000; i++) {
adder.increment();
}
})
)
.collect(Collectors.toList());
// 创建 9 个线程,每个累减 10000 次
List<CompletableFuture<Void>> cfList2 =
Stream.of(new Integer[9])
.map(item -> CompletableFuture.runAsync(
() -> {
for (int i = 0; i < 10000; i++) {
adder.decrement();
}
})
)
.collect(Collectors.toList());
cfList1.addAll(cfList2);
CompletableFuture.allOf(cfList1.toArray(new CompletableFuture[0])).join();
System.out.println(adder.longValue());
}
@Test
public void testLongAccumulator() {
LongAccumulator accumulator = new LongAccumulator((left, right) -> left * right, 100);
accumulator.accumulate(2);
System.out.println(accumulator.get());
}LongAdder 原理
LongAdder 基于分段 (分散热点) 的思想,将对一个值的 CAS 操作分散成了对多个值的 CAS,在获取值时进行 sum 操作 (未加锁,最终一致性),减少了高争用时 CAS 的空转。
LongAdder 继承自 Striped64,其中有几个关键的成员属性:
// CPU 个数,cells 数组的最大长度
static final int NCPU = Runtime.getRuntime().availableProcessors();
// cells 分段数组,size 为 2 的幂
transient volatile Cell[] cells;
// 低争用时使用的值
transient volatile long base;
// cells 数组创建或扩容时的锁
transient volatile int cellsBusy;下面是 LongAdder 的 add() 方法:
public void add(long x) {
/* 声明了几个变量:
cs -> cells 数组
b -> 低争用时用的值,即 base
v -> 当前线程 hash 后对应的 cell 中存储的值
m -> cells.size - 1,用来 hash 取模
c -> 当前线程 hash 后对应的 cell
*/
Cell[] cs; long b, v; int m; Cell c;
// 如果 cells 数组不为空,或在 base 上 cas 失败(可能高并发)
if ((cs = cells) != null || !casBase(b = base, b + x)) {
// 获取到当前线程的一个标识
int index = getProbe();
// 假设在当前线程对应的 cell 上没有发生争用
boolean uncontended = true;
// 如果 cells 数组为空
if (cs == null || (m = cs.length - 1) < 0
// 如果当前线程对应的 cell 为空
|| (c = cs[index & m]) == null
// 如果在当前线程对应的 cell 上发生争用
|| !(uncontended = c.cas(v = c.value, v + x))
)
// 创建/扩容 cells 数组
longAccumulate(x, null, uncontended, index);
}
}下面是 Striped64 的 longAccumulate() 方法:
final void longAccumulate(long x, LongBinaryOperator fn, boolean wasUncontended, int index) {
if (index == 0) {
ThreadLocalRandom.current(); // force initialization
index = getProbe();
wasUncontended = true;
}
// collide = false 假设创建 cell 未冲突
for (boolean collide = false;;) { // True if last slot nonempty
Cell[] cs; Cell c; int n; long v;
// case 1:在对应的 cell 槽位上 cas,扩容
if ((cs = cells) != null && (n = cs.length) > 0) {...} // 下一个代码片段单独摘出
// case 2:初始化 cells 分段数组,cas 方式设置 cellsBusy
else if (cellsBusy == 0 && cells == cs && casCellsBusy()) {
try {
// 双重检测,防止其他线程已经初始化了 cells
if (cells == cs) {
Cell[] rs = new Cell[2];
// 取模得到对应的 cell 槽位并初始化
rs[index & 1] = new Cell(x);
cells = rs;
break;
}
} finally {
cellsBusy = 0;
}
}
// case 3:fall back 兜底操作,再尝试在 base 上 cas
else if (casBase(v = base, (fn == null) ? v + x : fn.applyAsLong(v, x)))
break;
}
}下面是 Striped64 的 longAccumulate() 方法中的 case 1:
// ...
// case 1:在对应的 cell 槽位上 cas,扩容
Cell[] cs; Cell c; int n; long v;
// 如果 cells 数组不为空
if ((cs = cells) != null && (n = cs.length) > 0) {
// 如果对应的 cell 为 null
if ((c = cs[(n - 1) & index]) == null) {
// 尝试乐观创建 cell
if (cellsBusy == 0) {
Cell r = new Cell(x);
// cas 设置 cellsBusy 锁标志
if (cellsBusy == 0 && casCellsBusy()) {
try {
Cell[] rs; int m, j;
// 双重检测,确定未被其他线程初始化
if ((rs = cells) != null && (m = rs.length) > 0 && rs[j = (m - 1) & index] == null) {
rs[j] = r;
break;
}
} finally {
cellsBusy = 0;
}
continue; // Slot is now non-empty
}
}
// 创建 cell 时未发生冲突
collide = false;
}
// 否则如果对应的 cell 不为空,且在这个 cell 上 cas 冲突,给个机会重新 hash
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash,最后面调用了 advanceProbe() 方法
// 如果在对应的 cell 上 cas 成功,break
else if (c.cas(v = c.value, (fn == null) ? v + x : fn.applyAsLong(v, x)))
break;
// 如果超过 cpu 核数,或 cells 数组被其他线程修改过了
else if (n >= NCPU || cells != cs)
collide = false; // At max size or stale
else if (!collide)
collide = true;
// 扩容
else if (cellsBusy == 0 && casCellsBusy()) {
try {
// 双重检测
if (cells == cs) // Expand table unless stale
// n << 1 表示扩容乘以 2
cells = Arrays.copyOf(cs, n << 1);
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
// 重新 hash
index = advanceProbe(index);
}ThreadLocal
线程本地变量,通常是类的私有静态变量。
下面是一个 demo:
@Test
public void testThreadLocal() throws InterruptedException {
// 声明一个 ThreadLocal 并初始化值
ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);
ExecutorService pool = Executors.newFixedThreadPool(2);
for (int i = 0; i < 10; i++) {
pool.execute(()->{
try {
String tName = Thread.currentThread().getName();
System.out.println(tName + "-before-" +threadLocal.get());
threadLocal.set(threadLocal.get() + 1);
System.out.println(tName + "-after-" +threadLocal.get());
} finally {
// 对于使用线程池来说,一定要 remove
// 否则可能影响业务正确性,或内存泄漏
threadLocal.remove();
}
});
}
Thread.sleep(2000);
}- Thread、ThreadLocal、ThreadLocalMap 三者的关系:
- 每一个 Thread 中都包含了一个 ThreadLocal.ThreadLocalMap 属性;
- ThreadLocalMap 是 ThreadLocal 的静态内部类,保存着以 threadLocal 为 key 的 entry;这个 Entry 是 ThreadLocalMap 的静态内部类,继承了 WeakReference。
可以理解为:Thread 是线程实体;ThreadLocal 是线程本地变量访问器;ThreadLocalMap 是线程本地变量存储器。通过 threadLocal 对象,获取对应的变量。
下面是 ThreadLocal.get() 方法:
public T get() {
Thread t = Thread.currentThread();
// 拿到当前线程对应的 threadLocalMap
ThreadLocalMap map = getMap(t);
if (map != null) {
// 通过 threadLocalMap 拿到 key 为当前 threadLocal 的 entry
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}ThreadLocalMap.Entry 为什么要继承 WeakReference?
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
// key 是弱引用,指向 threadLocal 对象
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}参考前面的 demo,假设强引用局部变量 threadLocal 使用完毕后释放,而线程池中的线程所持有的 threadLocalMap 中的 key 也是对 threadLocal 的强引用,那么 threadLocal 将不会被 GC 回收,造成内存泄露。
但是这样还有一个问题就是 threadLocalMap 将有一个 key 为 null 的脏 entry,对于这种情况,在 get()、set()、remove() 中会有兜底的操作 expungeStaleEntry() 来清除脏 entry。这就要求我们最好手动调用 remove() 方法。
Note
- Reference:强引用 (默认),如果根可达,则不会被回收;
- SoftReference:软引用,内存不足时,即使根可达,也会被回收,适用于缓存数据;
- WeakReference:弱引用,只要 GC,都会被回收;
- PhantomReference:虚引用,任何时候都会被回收,且调用 get() 方法总是返回 null,必须和引用队列 ReferenceQueue 配合使用,当虚引用对象被回收时,会被添加到关联的引用队列中,目的是得到一些通知。
AQS
AQS(AbstractQueuedSynchronizer) 是 JUC 的基石,CountDownLatch、ThreadPoolExecutor、ReentrantLock、Semaphore 等同步器或锁的实现都是基于 AQS。
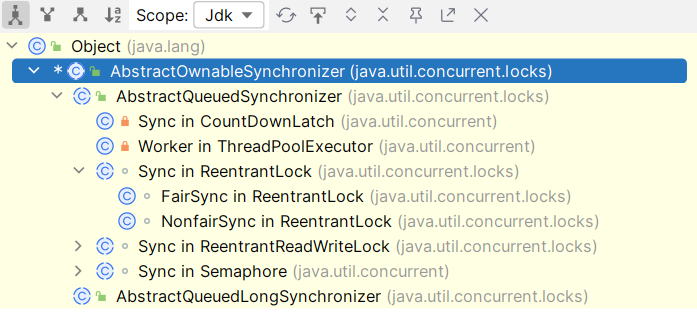
AbstractOwnableSynchronizer:是 synchronizer(同步器) 的抽象基类;AbstractQueuedSynchronizer:AQS 抽象类是创建其他锁和同步类的框架 (基石),屏蔽了同步状态、同步队列、阻塞、等待与唤醒等细节;AbstractQueuedLongSynchronizer:与 AQS 相同,唯一区别是与状态有关的变量都定义为 long 类型。
JUC 中锁的实现一般是通过组合的方式,在类中声明一个 AQS 的子类来进一步使用。例如在 ReentrantLock 中有一个抽象静态内部类 Sync 继承了 AQS,还有两个 Sync 的实现类 FaitSync 与 NonfairSync 分别实现公平与非公平的逻辑 (公平与非公平的区别在于新来的线程是先排队,还是直接参与竞争,而已经排队的线程还是会按照队列顺序获取锁)。
AQS 抽象类中拥有一个 volatile int state 和一个基于CLH 锁思想的队列。state 表示锁是否被持有,队列中的 Node 封装了排队线程的状态。
CLH (Craig, Landin, and Hagersten) 锁以三位提出者命名,是一种基于链表的自旋公平锁。
该链表有一个虚拟的队尾节点 Tail (共享),当有一个线程想要获取锁时,创建一个新节点 newNode 插入队尾:1.对 Tail 使用 getAndSet 原子操作将 Tail 的前驱节点置为 newNode,并得到旧的前驱节点 oldPreNode;2.将 newNode 的前驱节点置为 oldPreNode;第一步是原子性的,第二步操作的是线程本地变量。每个节点都不断的检查其前驱节点的 locked 状态,一旦前驱节点 locked == false,当前线程就认为自己获取了锁。
释放锁时,当前持有锁的线程只需将其节点的状态设置为已释放,这样它的后继节点就可以检测到锁变为可用状态,不需要显式出队列,因为队列中的节点只依赖于前驱节点。
CLH 锁解决了什么问题?
普通的自旋锁是多个线程对一个原子变量进行 CAS 操作。存在两个问题:
1.可能导致饥饿问题 (非公平);
2.存在性能问题,原子变量需要在 CPU Cache 中频繁同步保证线程可见性。而 CLH 锁解决了上述问题。
1.基于队列实现公平;
2.锁状态不再是原子变量而是前驱节点的状态;
3.释放锁只需要当前线程修改自己节点的状态,不需要 CAS 修改原子变量,进一步减少了开销。
AQS 基于 CLH 的理念做了改进与扩展,例如扩展了节点状态、加入了阻塞/唤醒机制。
Node 的状态包含:
- CANCELLED:表示线程由于超时或中断等原因被取消了获取锁的操作,将会被移出队列;
- SIGNAL:表示当前节点释放锁后需要唤醒后继节点;
- CONDITION:表示该节点目前位于条件队列中,而不是同步队列,正在等待某些条件满足后重新进入同步队列尝试获取锁;
- PROPAGATE:用于共享模式下的锁传播,例如读写锁,当前线程获取到了读锁,则应该唤醒 (传播) 后续期望获取读锁的线程。
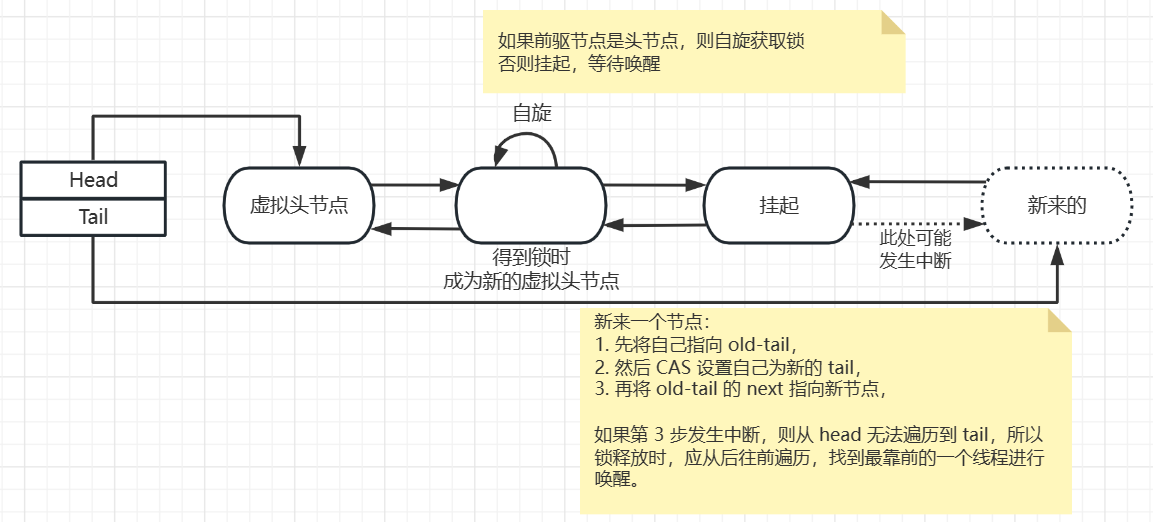
AQS 同步队列是一个双向链表。由于 AQS 使用阻塞代替自旋,阻塞等待状态的线程无法主动感知前驱节点的状态变化,因此当某线程释放锁时,需要显式通知唤醒后继节点。
Tail 节点有何作用?当插入新的队尾节点时,无法保证旧队尾节点的后继节点指针一定更新成功。所以在释放锁时,如果当前节点的后继节点非法,则应当从 Tail 向前遍历找到正确的后继节点进行唤醒。
当第 1 个线程来获取锁时,使用 cas 设置 state = 1,表示锁正在被持有中 (不会进入队列)。接着第 2 个线程期望获取锁时,cas 操作失败,则将代表该线程状态的节点加入队尾,该线程不会立即进入阻塞状态,而是经过短时间的自旋,如果还没有获取锁,则设置前驱节点状态为 SIGNAL,以便前驱节点释放锁时,能唤醒自己。目的是减少线程上下文切换开销。步骤如下图所示:
注意虚拟头节点只适用于初始化同步队列,当队列中有节点获取锁后,它会成为新的头节点。