数据类型 & 运算符
| 类型 | 长度/字节 | 备注 | 对应包装类 |
|---|---|---|---|
| byte | 1 | -128~127 | Byte |
| short | 2 | 2^15=32768 | Short |
| int | 4 | 2^31=2147483648 | Integer |
| long | 8 | 2^63 | Long |
| float(F) | 4 | 6~7 有效位 | Float |
| double | 8 | 15~16 有效位 | Double |
| char | 2 | Unicode 编码 | Character |
| boolean | 1 | 只有 true 和 false 两种表示形式 | Boolean |
| String | * | 不可变类 | * |
| 数组 | * | 特殊的 Object | * |
-
Java 没有无符号形式;
-
byte 能表示 -128~127 是因为补码表示有两种零(0/1,000 0000),所以用负零 1,000 0000 表示 -128,还有就是因为 -127=(1,000 0001) 再减 1 就变成了 -128=(1,000 0000);
-
局部变量使用前必须要初始化,成员变量在类加载准备阶段赋“0”值,初始化阶段赋初值;
-
boolean 默认为 false,String 默认为空串“ ”;
-
Java 整形默认为 int,浮点型默认为 double,float 需要加后缀 F;
-
byte 和 short 做运算为了不溢出都会转成 int;
byte b1 = 1; byte b2 = 2; //b1 = b1 + b2; 报错 b1 = (byte) (b1 + b2); // √ 溢出会截掉高位 -
字面量可以使用下划线分割,编译器会去除他们:1_000_000;
-
char 赋值时字面量要用单引号括起来
char c1 = 'A',JVM 使用 UTF-16 编码,赋编码值不用单引号char c2 = 65; -
String 在 1.9 以前内部使用
char[]表示,1.9 及以后使用byte[]和一个编码标志位 (表示使用 LATIN1 or UTF16),当字符串仅包含 ASCII 字符时,使用 LATIN1 编码 (1 字节/字符),否则使用 UTF-16 编码 (2 字节/字符),目的是能省则省;
字符集与编码规则
- Unicode 是字符集,为每一个字符分配一个二进制 ID(称为码点、码位、CodePoint),虽然定义了码点,但是没有规定如何存储与读取。例如 UCS-4 标准使用 4 个字节为全世界的字符分配了 ID,但是我们知道英文的 ID 都是靠前的(想想 ASCII 编码,一字节就够了),如果都用 Unicode 作为编码表示,那英文前面一串 0,浪费了太多空间,所有才有了一系列的编码规则。
- UTF-8 是编码规则,定义了将码点转换为字节序列的规则,是 Unicode 的一种实现方式;具体实现如下:
- 对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 Unicode 码;
- 对于 n 字节的符号(n > 1),第一个字节的前 n 位都设为 1(这样做计算机读到几个 1 就知道了要往后读几个字节),第 n + 1 位设为 0,后面字节的前两位一律设为 10,空余的二进制位从后往前依次填充这个符号的 Unicode 码;
Unicode符号范围 | UTF-8编码方式 (十六进制) | (二进制) 0000 0000-0000 007F | 0xxxxxxx 0000 0080-0000 07FF | 110xxxxx 10xxxxxx 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
- 现在知道为什么 UTF-8 汉字占三字节,因为汉字 Unicode 从 4E00-9FA6,要 15-16 位,而 UTF-8 的第二行只有 11 个空位,不够,所以用第三行,即占三个字节;
System.out.println("字".getBytes(StandardCharsets.UTF_8).length);// 3 System.out.println("字".getBytes(StandardCharsets.UTF_16).length);// 4 System.out.println("汉字".getBytes(StandardCharsets.UTF_16).length);// 6 // 为什么是4和6,因为前面有个FE或FF表示大小端
- JVM 运行时内部使用的是 UTF-16 编码,它分为基本平面 (使用 1 个 char,2 字节,即码点从
U+0000到U+FFFF的字符) 和增补平面 (使用 2 个 char,分别是高代理项和低代理项,4 字节,码点大于U+FFFF的字符)。这样做的好处是利于随机访问,例如调用charAt(int),由于 UTF-8 是变长的,只能从头遍历,而 UTF-16 可以直接获取,但要注意返回的是单个 char,若字符属于增补平面,应使用codePointAt(int)String str = "A😀B"; System.out.println("使用 length(): " + str.length()); // 输出 4,因为 "😀" 占 2 个 char System.out.println("使用 codePointCount(): " + str.codePointCount(0, str.length())); // 输出 3 // 使用 charAt 会得到错误结果 System.out.println("使用 charAt(0): " + new String(Character.toChars(str.charAt(0)))); // 输出 A System.out.println("使用 charAt(1): " + new String(Character.toChars(str.charAt(1)))); // 输出 ? System.out.println("使用 charAt(2): " + new String(Character.toChars(str.charAt(2)))); // 输出 ? System.out.println("使用 charAt(3): " + new String(Character.toChars(str.charAt(3)))); // 输出 B // 使用 codePointAt,如果 index 指向高代理项,且 index+1 指向低代理项,则返回完整的 32 位码点 System.out.println("使用 codePointAt(0): " + new String(Character.toChars(str.codePointAt(0)))); // 输出 A System.out.println("使用 codePointAt(1): " + new String(Character.toChars(str.codePointAt(1)))); // 输出 😀,高代理项可以返回完整的码点 System.out.println("使用 codePointAt(2): " + new String(Character.toChars(str.codePointAt(2)))); // 输出 ? 指向低代理项,无法返回完整的码点 System.out.println("使用 codePointAt(3): " + new String(Character.toChars(str.codePointAt(3)))); // 输出 B // 使用 offsetByCodePoints 可计算第 n 个码点的起始 char 对应的 index System.out.println("使用 offsetByCodePoints(0): " + new String(Character.toChars(str.codePointAt(str.offsetByCodePoints(0, 0))))); // 输出 A System.out.println("使用 offsetByCodePoints(1): " + new String(Character.toChars(str.codePointAt(str.offsetByCodePoints(0, 1))))); // 输出 😀 System.out.println("使用 offsetByCodePoints(2): " + new String(Character.toChars(str.codePointAt(str.offsetByCodePoints(0, 2))))); // 输出 B
-
类型转换
-
自动转换:char>int>long>float>double
-
强转字节不够的时候会直接截断高位,产生错误结果,例如 (byte) (0x1_0000_0000) = 0;
-
任何类型和 String 做运算都会自动转型成 String;
-
装箱、拆箱、字符串转化:
int a = 1; Integer aa; String str; //装箱 aa = Integer.valueOf(a); //拆箱 aa.intValue(); // 其实就相当于get方法,get Value属性; //Object->字符串 str = String.ValueOf(a); str = a + "";// 这个最方便 //字符串->基本型 a = Integer.parseInt(str);
-
-
包装类
-
整形和浮点型都继承了抽象类 Number;
-
包装类有一个属性 value 放基本型,而且一旦包装就不能再改变;
//Integer类 private final int value; public Integer(value){ this.value = value; }
-
-
Java 中四种整形包装类都用数组缓存了 -128~127,因此在用
==比较这个范围的包装类时返回 true;// Byte中的一个内部类 ,其他整形同理 private static class ByteCache { private ByteCache(){} static final Byte cache[] = new Byte[-(-128) + 127 + 1]; static { for(int i = 0; i < cache.length; i++) cache[i] = new Byte((byte)(i - 128)); } } // Byte 的valueOf方法 public static Byte valueOf(byte b) { final int offset = 128; return ByteCache.cache[(int)b + offset]; } // Integer 中的 valueOf方法 public static Integer valueOf(int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); } // 若是new Integer(int x)的话,== 返回false-
Boolean 中参数为 String 的构造函数
public Boolean(String s) { this(parseBoolean(s)); } public static boolean parseBoolean(String s) { return ((s != null) && s.equalsIgnoreCase("true")); } // new Boolean("tRuE"); 传参只要是忽略大小写的true就是true,其他false;
-
-
String
// String 类中属性 private final char value[]; // 1.9 及之后 private final byte[] value; private final byte coder; // LATIN1 or UTF16-
intern()方法:-
JDK 1.7 之前,常量池位于方法区,intern 方法会将首次遇到的字符串 实例复制 到常量池中,再返回其引用;
-
JDK 1.8 之后,常量池搬移到堆中,intern 方法会将首次遇到的字符串实例的 引用添加 到常量池中,再返回其引用;
-
下面代码环境均为 jdk1.8:
String str1 = "abc"; // 首次遇到“abc”,加入到常量池 String str2 = "ab" + "c"; // 编译时优化,就是“abc” String str3 = new String("ab") + "c"; // 新开辟一个空间 存“abc”,即和上面俩没关系 System.out.println(str1 == str2); //true System.out.println(str1 == str3); //false System.out.println(str1 == str3.intern());//true 常量池中有“abc”的引用 System.out.println(str3 == str3.intern());//false intern返回的是str1的引用(因为“abc”首次出现是str1),和str3指向的堆内存的“abc”不是同一个 //分割线,和上面代码无关---------------- String str1 = new String("ab") + "c"; System.out.println(str1.intern() == str1); // true 常量池中的“abc”就是引用自new 的“abc”,因为首次出现
-
-
new String 不会将字符串的引用放入常量池中(误):
-
new String(“abc”) 中的参数 abc 字符串在类加载的时候也会存入常量池,但是 new 的时候是复制了一份放在堆中,并返回引用。
String str1 = new String("ab") + "c"; String str2 = "abc"; System.out.println(str1 == str2); //false,说明new String没往常量池中添加 //分割线--- String str1 = new String("ab") + "c"; str1.intern(); //调用intern()才会添加 String str2 = "abc"; System.out.println(str1 == str2); //true // 侧面说明直接创建字符串会添加到常量池,所以不推荐使用new创建String;编译时就将已知的str(双引号创建的str)加入到了该类静态常量池,类加载时进入运行时常量池。
-
-
-
数组
-
数组是一个特殊的对象,也继承自 Object,它也封装了属性和一些方法,那它到底是什么类型呢?
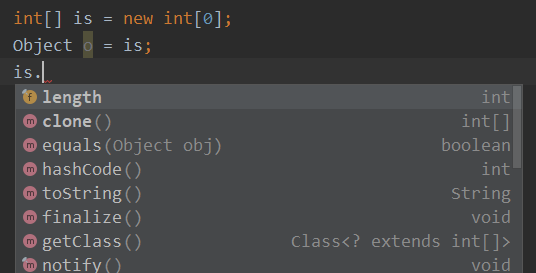
//通过getClass.getName看看它是什么类型 int[] arr1 = new int[0]; Integer[] arr2 = new Integer[0]; String[] arr3 = new String[0]; String[][] arr4 = new String[0][]; System.out.println(arr1.getClass().getName()); System.out.println(arr2.getClass().getName()); System.out.println(arr3.getClass().getName()); System.out.println(arr4.getClass().getName()); // 结果如下: // [I // [Ljava.lang.Integer // [Ljava.lang.String // [[Ljava.lang.String // 使用IDE也搜不到这几个类,可以理解为数组类是JVM内部维护的类。- 简单理解就是:数组是一个数据结构,体现在内存上就是一块连续的内存分成若干小块,每个小块可以存储相同类型数据,而 JVM 帮我们把它封装成了一个特殊的对象,可以通过
[ ]访问它的属性,还可以调用它的方法。 - 一维数组声明时必须指定长度,初始化值为 0;
- 二维数组声明必须指定行数,初始化值为 0;实质是数组的数组,所以每一行可以有不同数的列;
- Java 允许数组长度可以为零;
- String 数组元素默认初始化为 null 而不是空串“ ”;
- Arrays.toString(Object []) 返回一个包含数组所有元素的字符串 [1,2,3,…];
- 数组拷贝使用 Arrays.copyOf(s,s.length());
- 简单理解就是:数组是一个数据结构,体现在内存上就是一块连续的内存分成若干小块,每个小块可以存储相同类型数据,而 JVM 帮我们把它封装成了一个特殊的对象,可以通过
-
-
运算符
-
两个操作数都是整数时,是整数运算;否则都会扩展精度;
-
整数/0 = 算数异常;
-
浮点数/0 = infinity 无穷大;
-
逻辑运算符:&& || ! == !=
-
位运算:& | ~ ^(异或) << >> >>>
- >> 算术移位,高位填符号位;
- >>> 逻辑移位,高位填 0;
- 不存在
<<<因为 原码补码左移低位都填 0,其实算数移位和逻辑移位也就只是针对补码 (而且是表示负数的补码) 的右移来说的;
-
& 和 && 的区别
-
都是可以当做逻辑运算符,要求两个操作数都是 boolean 型;而且&& 具有短路功能,即第一个条件为 false,第二个不用判断。
-
& 还可以作为位运算符,要求操作数不是 boolean,有啥用呢,比如我们可以使用下面的操作来取一个整形的低几位:
System.out.printf("%x", 0xff & 128);// 7f ,即低八位 -
判断奇偶:
public static boolean isOdd(int a){ if ((a & 0b1) == 1) return true; return false; }
-
-
优先级与结合性:

-
对象 & 类
- 一些概念:
- 现实中万事万物皆是对象,编程世界中对象是具有一定属性和方法的封装体;计算机中对象是一块内存;
- 类是对象的模板,是一系列具有相同属性和方法的对象的抽象集合。
- 封装:隐藏自己的成员属性和某些方法,只将对外提供的方法暴露出来;
- 继承:基于一个已存在的类构造一个新类;
- 多态:多种状态;
- 构造方法:
- 没有返回值,与类同名;伴随着 new 操作被调用;
- 子类初始化一定会调用父类构造方法(抽象类也有构造方法);
- 子类构造方法调用父类构造方法必须写在第一行,没有显式调用会自动调用父类默认构造方法(无参构造方法),若父类无默认构造方法,则编译会报错;
- 静态块:static{ },类加载时候执行;
- 注意:静态变量的赋值语句和静态块同等级,按代码书写顺序执行。
- 初始化块:{ },随着对象的创建而执行,在构造方法之前执行;
- 析构方法:
- 会在 GC 回收对象之前调用,但不保证会执行完成;
- 一般不建议使用,因为我们不知道 GC 回收对象的准确时机,也就不知道析构执行的时机;
- 一个对象只会执行一次;
- 静态属性与静态方法:
- 属于类但不属于对象的属性和方法,随着类的加载而加载;
- 静态变量:static 属性由所有实例共享,例如可以使用静态变量统计一下这个类 new 了多少次实例;
- 静态常量:使用 static final 修饰,例如定义很多常量值,还有经常使用的 System.out 就是一个 PrintStream 静态常量;
- 静态方法:静态方法不能访问对象的状态,只能访问类中的静态属性;可以由类名.方法名调用,当然也可以使用对象名调用但是容易造成混淆一般不使用;
- main() 方法:程序的入口,每一个类可以有一个 main 方法,使用 java 命令执行哪个类就会从哪个类进入,如果一个类中有 main 方法但是没有从它进入,那这个 main 永远不会执行。
- 参数传递:
- 基本类型按值传递,引用类型按引用传递。虽然这个说法具有一定广泛性但却是 错误 的;
- 实际上引用类型传递的是引用的拷贝,也是值传递,代码验证:
Stu x = new Stu("x");
Stu y = new Stu("y");
swap(x,y);
public static void swap(Stu a,Stu b){
Stu temp = a;
a = b;
b = temp;
}
// 这样想要交换两个对象是不行的,交换的是引用的值,对象在内存中并没有发生交换。-
方法重载:
- 一个类中有多个方法具有相同的方法名,不同的参数列表,称为重载;
- 方法签名 = 方法名 + 参数列表;
- 关于异常抛出、修饰符、返回值都没有限制;
- 一个类中有多个方法具有相同的方法名,不同的参数列表,称为重载;
-
可变参数:
- 可变参数等价于数组,可以互相替换,代表同样的参数列表,即不能把二者互相替换达到重载的目的;
- 必须放在最后,否则会引起歧义;
public static double max (double ... values) { double largest = 0.0; for(double v : values) if(v > largest) largest = v; return largest ; } -
包:
- 包的作用是确定唯一的类,因此建议包名为公司域名反写,因为域名肯定是唯一的;
- 静态导入(不常用):导入静态方法和静态属性;例如可以使用 import static java.lang.System.* ,这样输出的时候可以直接写 out.println(); 甚至导入 java.lang.System.out 可以直接写 println(), 当然前提是没有冲突。
- 可以通过打 jar 包的方式将包密封起来。
-
访问权限修饰符:
- 类:只有 public 和 缺省
- 每个 .java 文件只能有一个 public 的 class,且必须和文件名相同;;
- 可以没有 public 的 class
- 内部类 相当于类的成员,可以使用 protected、private 修饰,可见性同成员变量一样;
- 缺省则只能被同包访问;
- 每个 .java 文件只能有一个 public 的 class,且必须和文件名相同;;
- 方法与属性:
- 类:只有 public 和 缺省
| 作用域与可见性 | public | protected | default | private |
|---|---|---|---|---|
| 当前类 | √ | √ | √ | √ |
| 同包类 | √ | √ | √ | x |
| 不同包子类 | √ | √ | x | x |
| 其他 | √ | x | x | x |
-
关于继承:
- 概念:基于一个已存在的类构造一个新类;
- 类只能单继承,可以多实现;接口无限制但不能循环,接口的实现也具有传递性;
- 子类初始化前必须先初始化父类;若父接口中有 default 方法,或使用了父接口的常量,则必须先初始化父接口,否则不需要初始化父接口;
- 子类可以继承父类所有成员方法和属性;
- 对于 private 也能继承,只不过不能直接访问,需要通过访问器,通过 this 都不行;
- 对于 static 方法和属性(包括 static final 属性),继承的是使用权,即(在有访问权限的前提下)可以通过子类的类名或实例名调用父类中的静态方法和属性,不存在重写一说,若企图“重写”则会隐藏父类的静态方法;
- 如果这点不考虑的话,其实可以说成是:子类可以继承父类所有的 成员 变量和方法,静态是属于类的,不属于类的实例;
- 对于 final 方法与属性,方法可以继承但是无法重写,父类 final 属性若在父类构造器或初始化块中赋值,则可以通过子类构造器或初始化块对继承下来的 final 属性赋值,否则无法修改;
- 子类无法删除继承下来的任何属性和方法,可以通过声明同名属性来隐藏父类属性;
-
方法重写:
- 子类方法和父类方法拥有 相同的方法签名,且返回值必须 兼容;
- 这个兼容有个名词叫 协变,就是子类重写的返回值范围要小于等于父类的返回值范围。
- 修饰符:
- 子类访问修饰符必须大于等于父类访问修饰符。
- final 和 static 都不能重写,但是子类按照相同的方法签名“重写”不会报错,这时因为编译器将这个“重写”的方法当做子类自己的方法;通过声明父类创建子类,再调用该方法即可证明,发现调用的始终是父类的方法,即没有发生多态,也就没有发生重写。
- 异常:不能抛出比父类范围大的异常;
- 子类方法和父类方法拥有 相同的方法签名,且返回值必须 兼容;
-
多态:
-
可以 声明父类创建子类,即父类引用可以指向子类对象,反之不能;
- 父类能出现的地方都可以使用子类置换;
-
声明父类就只能调用父类拥有的方法;
- 即不能调用子类独有的方法,只能调用父类拥有的方法,但是会调用子类重写的方法;
- 这时候想要调用子类独有方法就得 强转 为子类;
-
避免多态的例子:
- 子类数组的引用可以直接赋值给父类数组引用,这时父子类引用都指向同一个含有子类元素的数组,这时假设通过父类引用
father[0]在数组里面添加一个父类元素,再通过子类引用son[0]去调用子类独有的方法,就会报 ArrayStoreException,因为实际存的是父类元素,并没有子类独有的方法。 - 上面是书上看到的,测试的时候发现父类元素放不进去(jdk1.8),直接报异常,不知道是不是 JDK 后面版本优化了:
Son[] sonArray = new Son[3]; sonArray[1] = new Son(); sonArray[2] = new Son(); Father[] fatherArray= sonArray; fatherArray[0] = new Father();// java.lang.ArrayStoreException - 子类数组的引用可以直接赋值给父类数组引用,这时父子类引用都指向同一个含有子类元素的数组,这时假设通过父类引用
-
-
强转:
- 使用强转前最好使用 instanceof 进行判断,因为有可能会报 ClassCastException;
- null instanceof object 会返回 false;
- 使用强转前最好使用 instanceof 进行判断,因为有可能会报 ClassCastException;
-
final:
- final 修饰的类不能被继承,类中方法也默认变为 final;
- final 修饰的方法可以被继承但不能被重写;
- final 修饰的属性构造后不能再赋值(引用不能修改,引用的内容可以);
-
抽象类:
- 关键字 abstract 声明的类称为抽象类,与普通类的最大区别是不能实例化;
- 不含抽象方法的类也可以声明为 abstract 类,含有抽象方法的类必须声明为 abstract 类;
- 可以声明抽象类创建非抽象子类;
-
枚举类:
//假如没有枚举 class Week1 { public static final int MONDAY = 1; public static final int TUESDAY = 2; public static final int WEDNESDAY = 3; public static final int THURSDAY = 4; public static final int FRIDAY = 5; public static final int SATURDAY = 6; public static final int SUNDAY = 7; } //使用枚举 enum Week { MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY }-
枚举类 本质 是一个继承 java.lang.Enum 的 final 类,枚举值就是该类的实例;
$ javap Week.class Compiled from "TestEnum.java" final class Week extends java.lang.Enum<Week> { public static final Week MONDAY; public static final Week TUESDAY; public static final Week WEDNESDAY; public static final Week THURSDAY; public static final Week FRIDAY; public static final Week SATURDAY; public static final Week SUNDAY; public static Week[] values(); public static Week valueOf(java.lang.String); static {}; }
-
-
接口:
- 概念:接口不是类,而是对类的一组规则的描述,一个类要实现某接口就要遵从该接口定义的规则,即实现接口中的方法;
- 接口中的方法默认都是 public abstract,属性默认都是 public static finall,不能含有普通成员变量;
- 传递性:父类实现了接口,子类也就实现了该接口(instance 返回 true),继承了父类重写接口的方法。
- 概念:接口不是类,而是对类的一组规则的描述,一个类要实现某接口就要遵从该接口定义的规则,即实现接口中的方法;
-
Java SE8 允许接口中增加静态方法,目的是减少 伴随类,比如:我们有时候想要调用某一个类的某个非常简单地静态方法,若这个方法在这个类实现的接口中实现了,那么我们就可以通过接口来使用该方法,而不用再加载这个类。
-
可以将接口中方法声明为 default 并提供默认实现,这样做的意义就在于:假如某个接口中有多个方法,而我们常用的就只是一两个,实现该接口还要重写其他不用的方法,非常不方便,而且代码看起来也杂乱;使用 default 对方法修饰就可以提供默认实现(实现类中就不会提示重写),注意区别于静态方法,default 方法不能通过接口调用,需要实现类的对象来进行调用;
-
标记接口:只有一个空接口,唯一的目的就是标记身份,使用 instanceof 判断;
-
默认方法冲突:
- 超类优先,由此可以看出来,尽量不要让接口中的 default 方法重写 Object 中的 toString、equals 等方法,因为默认情况下使用的还是 Object 类的方法;
- 接口 IA 和 IB 有相同方法声明(返回值、名称、参数列表)的方法,分下面情况:
- 只要有一个接口中的该方法声明为 default,就会冲突,需要在实现的时明确指定,例如
return IA.super.function(); - 两接口的该方法都没有声明 default,就不会冲突,因为实现类要么实现要么不实现,随实现类而定;
- 只要有一个接口中的该方法声明为 default,就会冲突,需要在实现的时明确指定,例如
- 接口 IA 和 IB 有相同方法声明(返回值、名称、参数列表)的方法,分下面情况:
class FA { public void print() { System.out.println("FA.print"); } } interface IA { default void print() { System.out.println("IA.print"); } } interface IB { default void print() { System.out.println("IB.print"); } } class SonA extends FA implements IA, IB { public static void main(String[] args) { SonA s1 = new SonA(); s1.print(); // 不重写的话默认调用父类 } @Override public void print() { super.print(); //指定调用父类,等价于不重写 //IA.super.print(); //指定调用IA //IB.super.print(); //指定调用IB } } - 超类优先,由此可以看出来,尽量不要让接口中的 default 方法重写 Object 中的 toString、equals 等方法,因为默认情况下使用的还是 Object 类的方法;
-
内部类:
-
当两个对象有 紧密的组合关系 时,使用内部类。例如 Person 类包含 Heart 类,如果 Heart 类来自外部则无法说明其关系的紧密,也无法使用内部类的一些特性;
-
本质 也是一个类的成员属性,可以用修饰符修饰;
-
内部类编译后生成独立的
外部类$内部类.class,没有 主动引用 的话,外部类加载不会引发内部类加载;- 所以可以用来实现懒加载单例。
-
内部类可以访问其外部类的 所有 数据;外部类要访问内部类的成员时,必须要建立内部类的对象;
- (非静态)内部类对象不能独立于外部类对象而存在;
- 内部类中隐藏了指向外部类的引用
OuterClass.this;
//创建内部类的方式 Outer.Inner inner = new Outer().new Inner(); //或者:(即必须借助外部类) Outer outer = new Outer(); Inner inner = outer.new Inner(); //例子 class Person { private boolean alive = true; class Heart { public void jump() { if (alive) System.out.println("-^-^-^"); else System.out.println("-------"); } // 可以直接访问外部类私有属性 public void setAlive(boolean b) { // 内部类中外部类引用不再是this,而是 外围类.this; Person.this.alive = b; } } public static void main(String[] args) { Person.Heart heart = new Person().new Heart(); heart.jump(); // -^-^-^ heart.setAlive(false); heart.jump(); // ------- } } -
非静态内部类中所有的静态属性都必须是 final;
- 这里的 final 静态属性指编译期常量,即基本型和用引号创建的 String;非静态内部类中不能有非编译期常量,即
static final String str = new String("xxx");这样的写法; - 非静态内部类中暗含了一个指向外部类的引用(通过内部类的构造方法传递),也是通过这个引用来引用外部类的属性,所以非静态内部类依赖于外部类,即 加载内部类之前必须先加载外部类,体现在代码上就是要用具体的外部类对象去创建内部类对象;
- 现在假设非静态内部类中存在 static 属性,则理应可以通过类名
Outer.Inner.属性名直接访问,但如果 Inner 没有被初始化过,这就会出错。Inner 的初始化依赖于 Outer,Inner 虽然是一个类,但本质是 Outer 的一个属性;声明为 final 的常量在编译期间就可以确认,通过Outer.Inner.属性名调用会经过 常量传递优化,直接将此常量传递到调用者的常量池中,不会引发内部类的加载,所以非静态内部类中只能有编译期常量;
- 这里的 final 静态属性指编译期常量,即基本型和用引号创建的 String;非静态内部类中不能有非编译期常量,即
-
非静态内部类不能有 static 方法;
- 道理同上。
-
-
静态内部类
- 在 内部类不需要访问外围类对象的时候 ,使用静态内部类。此时静态内部类就和外部类的其他静态属性一样,外部类加载的时候加载,可以独立于外部类存在;
- 静态内部类只能访问外部类的静态属性,原因和静态方法不能访问非静态属性一样,是由于生命周期造成的;
- 静态内部类不存在上述 static 必须修饰为 final 的问题;
- 打个比方:内部类描述了两个类之间的组合关系,如 Person 类、Heart 类、Hair 类;而关系紧密的使用普通内部类,如 Heart 类不能独立于 Person;关系不密切的使用静态内部类,如 Hair 类可以独立于外部类。
-
局部内部类
- 不能使用修饰符,作用域只在声明他的方法体中;
- 对外部完全隐藏,只有声明他的方法知道他的存在;
-
匿名内部类
-
本质:是一个 匿名的带有具体实现的子类;
-
不使用匿名内部类,我们需要:定义子类,重写方法,new 子类对象,调用方法;
-
使用内部类:
interface People{ void talk(); } People p = new People(){ @Override public void talk(){ System.out.println("p talk"); } }; p.talk();
-
异常
- 声明 ⇒ 捕获 ⇒ 抛出
- **声明 throw:**声明代码可能引发的异常;
- **捕获 catch:**当异常发生时,应当获取异常信息并作相应处理,通常是给用户以反馈;
- **抛出 throws:**将控制权从错误产生的地方转移给能够处理这种情况的错误处理器;
- 继承结构:
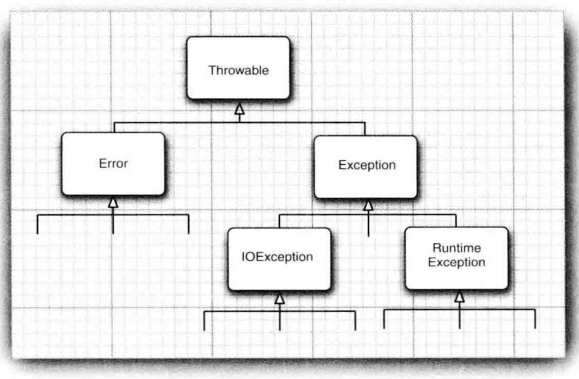
- Error:通常是系统内部的错误,如资源耗尽等,遇到此类错误,除了通知用户、保存当前数据外一般只能停机,我们对此没有控制能力;
- Exception:
- IOException:一般程序本身没有问题,但由于外部资源的异常而引发;
- RuntimeException:程序本身错误导致的异常;
- 注意:Runtime 具有混淆性,其实异常都是运行时期产生的;
- Checked 与 Unchecked 异常:
- Error 和 RuntimeException 称为非受查(Unchecked)异常,其他异常(IO、直接继承 Exception 的自定义异常等)称为受查(checked)异常;
- 任何代码都具有抛出 unchecked 异常的潜力,即我们 不用 throws 和 catch unchecked 异常,例如 ArrayIndexOutOfBoundsException,我们应集中注意去避免这些异常,而不是声明它发生的可能性;如果发生了,虚拟机会帮 catch(打印信息,停机);
- 我们何时应该 **throws 或 catch **checked 异常:
- 当调用了抛出 checked 异常的方法时;
- 当方法内 throw new checked 异常时;
- 子类方法重写抛出的受查异常范围不能比父类方法大,若父类方法没有抛出异常,则子类重写时也不能抛出,只能自己 catch;
- 自定义异常:
- 继承 Exception 或其子类;
- 两个构造器:默认 + 传递字符串,Throwable 的 toString 将会打印这个字符串;
- 捕获异常:
- try-catch-finally
- try 中代码抛出了一个 catch 中声明的异常类,那么 try 块剩余代码不执行,转去执行 catch 块代码;
- 如果 try 块中抛出了一个 catch 中未声明的异常,那么该方法将立即退出;
- finally 最后都会执行;
- catch 还是 throws:
- 知道怎么样处理就 catch,否则就 throws;
- 子类重写父类方法,父类方法又没有抛出异常,则子类只能自己 catch;
- catch 中还可以再 throw new 异常,目的是为了转换异常类型;
- 注意:有 return 时,return 在 try 块中,会在 return 执行之前执行 finally,若 finally 块也有 return 则会覆盖 try 块中的 return;
- try-catch-finally
- Closeable 接口:
- 我们通常使用 finally 释放资源,但当 try 块与 finally 块同时发生异常抛出时,finally 抛出的异常会覆盖掉 try 块抛出的异常,而我们通常需要的恰好就是 try 抛出的异常信息,JavaSE7 中实现了这个释放资源的快捷方式 try-with-resources;
- 凡是实现了 Closeable 接口的资源都可以通过声明在 try(…) 中来自动释放;
泛型
-
定义:泛型是参数化的类型
- 使用泛型可以使我们编写的代码被不同类型的对象所重用;
- 一些情形下我们不需要再使用 Object、强转等操作;
- 使得程序具有更好的可读性和安全性(编译器会进行类型检查);
-
泛型类:
class GenericClass<T, F, G> { private T first; private F second; private G third; public GenericClass(T first, F second, G third) { this.first = first; this.second = second; this.third = third; } public static void main(String[] args) { new GenericClass<Integer, String, Boolean>(1, "泛型类", true); } } -
泛型方法:
- 泛型方法不必一定定义在泛型类中;
- 使用
extends限定T的范围,使用&分割多个,称为 限定类型;
public static <T extends Comparable & Serializable> T max(T... a) { if (a == null || a.length == 0) return null; T max = a[0]; for (T t : a) { if (t.compareTo(max) > 0) max = t; } return max; } // 调用 GenericClass.<Integer>max(1,3,5); //一般不用写<>,编译器会根据我们写的参数自动确定类型 GenericClass.max(1,3,5); -
类型擦除:
- Java 实现的泛型是一种“伪泛型”,使用类型擦除机制;C++ 为每一个模板类型产生真实的类型,称为“模板代码膨胀”;
- 泛型类型对应着一个原始类型,类名就是擦除类型参数后的泛型类名;变量类型就是擦除类型变量,并替换为第一个限定类型(没限定类型就是 Object);如 GenericClass<T>擦除后成为:
class GenericClass{ private Object first; private Object second; private Object third; public GenericClass(Object first, Object second, Object third) { this.first = first; this.second = second; this.third = third; } // ...... } -
类型擦除对 参数或返回值是类型参数类型的方法 造成的影响:
// Pair类 封装某类型为一对
public class Pair<T> {
private T first;
private T second;
public Pair() {
}
public Pair(T first, T second) {
this.first = first;
this.second = second;
}
public T getFirst() {
return first;
}
public void setFirst(T first) {
this.first = first;
}
public T getSecond() {
return second;
}
public void setSecond(T second) {
this.second = second;
}
}
// DateInterval类 表示一时间段
class DateInterval extends Pair<LocalDate> {
// 重写父类方法,保证时间段为正值
@Override
public void setSecond(LocalDate second) {
if (second.compareTo(this.getFirst()) >= 0)
super.setSecond(second);
}
}
// main方法
public static void main(String[] args) {
Class<DateInterval> clazz = DateInterval.class;
Method[] methods = clazz.getMethods();
for (Method method : methods) {
System.out.println(method);
}
}
// 打印一下DateInterval的运行时方法发现结果包含下面两条setSecond方法:
// 1. public void DateInterval.setSecond(java.time.LocalDate)
// 2. public void DateInterval.setSecond(java.lang.Object)
//----上面是重写的,下面是继承的-----
// 对比get方法与setFirst方法:
// 3. public java.lang.Object Pair.getFirst()
// 4. public java.lang.Object Pair.getSecond()
// 5. public void Pair.setFirst(java.lang.Object)
// ……-
分析:
-
很明显,由于类型擦除,继承
Pair<LocalDate>,实际继承的是Pair,类型参数都替换为了Object,那为什么我们还可以重写setSecond(LocalDate second)方法而不报错呢?这就是 类型擦除与多态发生的冲突; -
当我们 试图重写 诸如此类方法,编译器为我们在 DateInterval 中生成**桥方法 (bridge method)**来解决这个问题:
- 为什么说是试图重写,因为这本来是不符合语法的,从父类继承下来的方法中并没有参数为 LocalDate 的 setSecond 方法;但是我们确实有这样的开发需求,所以让编译器为我们解决;
// 上述 2. public void DateInterval.setSecond(java.lang.Object)就是桥方法,方法体为: public void setSecond(Object second){ this.setSecond((LocalDate)second); } // 即就是调用我们重写的setSecond(LocalDate second)方法- 总结一下:编译器会根据我们是否重写了此类方法,而帮我们生成桥方法,生成桥方法也是重写父类方法的过程,即根据我们试图重写的方法,帮我们重写了参数为 Object 的方法;
-
另外,方法重写中的 返回值协变规则 也是运用桥方法实现的:
// 重写DateInterval 的 clone方法 // 实际类中存在两个clone方法 protected DateInterval clone() throws java.lang.CloneNotSupportedException; protected java.lang.Object clone() throws java.lang.CloneNotSupportedException -
那对于 get 方法这样返回类型是类型参数类型的呢?
- 像这样的方法,我们一般不会重写,因为调用这样的 get 方法,编译器会帮我们自动强转;
- 而非要重写的话,结论还是同上,可以重写生成桥方法,但是会生成两个返回值类型不同,方法签名相同的方法:
public java.lang.Object DateInterval.getSecond() public java.time.LocalDate DateInterval.getSecond()- 虽然编译器禁止我们写出这样的重载代码,但是它自己就这样写了,这是个特例;
-
-
其他要 注意:(大都是因为类型擦除所引起)
-
instanceof 与强转只能跟 原始类型 做判断;
//下面两种表达都是错误的 if(a instanceof Pair<String>); Pair<String> p = (Pair<String>) a; -
不要创建数组;
Pair<String>[] pairs = new Pair<String>[10]; // 分析:擦除后pairs变成了Pair[] 类型; -
不要使用带有类型变量的静态属性与方法;
- 泛型类的静态上下文中类型变量无效
-
注意擦除后的冲突;
boolean equals(T) ; // 擦除后,发生冲突 boolean equals(Object); -
Pair<Father> 与 Pair<Son>没有继承关系;
- 即不能企图声明父类指向子类,通配符解决了这个问题。
-
-
通配符
?:- 无限定通配符
?- 通常能见到
Collection<?>,表示未知、类型无关,只能调用类型无关的方法。
- 通常能见到
List<?> list = new ArrayList<>(); list.add(0); // 报错 list.add(null); // 正常 list.size(); // 正常- 子类限定
<? extends Father>,协变,只读,因为读取时可以声明父类指向子类,写入时无法确定实例的具体类型。
List<? extends Number> son = new ArrayList<Integer>(); List<? extends Number> brother = new ArrayList<Double>(); son.add(0); // 编译错误,因为编译器无法推断是哪个子类,无法保证类型安全 // 无论实际类型是什么,我们都可以使用 Number 接收它 Number n1 = son.get(0); // 正常 Integer n2 = son.get(0); // 编译错误- 超类限定
<? super Father>,逆变,只写;
List<? super Integer> grandMa = new ArrayList<Number>(); List<? super Double> grandPa = new ArrayList<Number>(); // 无论实际泛型参数是什么,只要它是 Number 或者 Number 的父类, // 例如 Object、Serializabel 我们都可以肯定任何 Number 或其子类对象的插入都是类型安全的 grandMa.add(0); // 正常 Number n1 = grandMa.get(0); // 编译错误,读取到的都是 Object 类 Number n2 = ((List<Integer>) grandMa).get(0); // 正常 - 无限定通配符
PECS (Provider Extends Consumer Super)
总的来说,上界 extends 使得泛型具有往上(向父类)兼容的特性,主要用于限制生产者(Producer),即我们可以从这样的集合中安全地读取元素。然而,下界 super 则使得泛型具有往下(向子类)兼容的特性,主要用于限制消费者(Consumer),即我们可以安全地向这样的集合中插入元素。
下面是 Collections 的 copy 方法:
public class Collections {
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
int srcSize = src.size();
if (srcSize > dest.size())
throw new IndexOutOfBoundsException("Source does not fit in dest");
if (srcSize < COPY_THRESHOLD ||
(src instanceof RandomAccess && dest instanceof RandomAccess)) {
for (int i=0; i<srcSize; i++)
dest.set(i, src.get(i));
} else {
ListIterator<? super T> di=dest.listIterator();
ListIterator<? extends T> si=src.listIterator();
for (int i=0; i<srcSize; i++) {
di.next();
di.set(si.next());
}
}
}
}
集合
- List 插入有序,可重复
- ArrayList 查询快、增删慢,线程不安全
- Vector 查询快、增删慢,线程安全
- LinkedList 查询慢、增删快,线程不安全
- Set 唯一,依赖于
hashCode()和equals()方法- HashSet 底层=hash 表,无序,可以有 null 值
- LinkedHashSet 底层=链表 +hash 表,插入有序,可以有 null 值
- TreeSet 底层=红黑树,有序,不能有 null 值
- Map 键值对,键唯一
- HashMap 无序,线程不安全,可以有 null 值
- HashTable(父类是 Dictionary) 无序,线程安全,不能有 null 值
- LinkedHashMap 无序
- TreeMap 有序
lambda
lambda 表达式是一个可以 推导、传递 的 代码块,主要解决了 Java 过分面向对象的缺点,因为我们有时候 只关注做什么产生什么结果,而不关注是 “谁” 用什么方法产生的这个结果,这个”谁“就是 lambda 帮我们省略的匿名对象。
格式
()表示参数列表,无参为空,参数类型一定时可以省略类型;->表示推导传递之意;{ }表示方法体,只有一条语句时可以省略花括号、分号和 return;
lambda 的推导作用
- 回想匿名内部类解决了什么样的问题,原本我们需要写一个类、继承接口、实现方法、在需要的地方 new 对象调用方法,匿名内部类让我们可以直接声明接口创建匿名实现类,并直接重写其方法,从而简化了步骤;而 lambda 表达式在这一基础上再次简化,更加方便我们使用,但是使用 lambda 推导是有条件的,那就是进行推导的接口必须是一个函数式接口;
- 函数式接口:有且只有一个抽象方法的接口,重载也不行;默认方法、静态方法、重新声明的 Object 方法都不考虑;
@FunctionalInterface注解可以检查该接口是否满足函数式接口条件;
// 函数式接口
@FunctionalInterface
interface People {
void talk(String s);
}
// 方法参数有一个函数式接口
public class MyLambda {
public static void talkSth(String s, People p) {
p.talk(s);
}
}
public static void main(String[] args) {
// 匿名内部类方式
MyLambda.talkSth("使用匿名内部类", new People() {
@Override
public void talk(String s) {
System.out.println(s);
}
});
// lambda方式
MyLambda.talkSth("使用lambda表达式", (s) -> System.out.println(s));
}-
lambda 传递作用——方法引用
- 上面 lambda 方式的代码还是显得有点冗余,可以传递方法引用简化:
MyLambda.talkSth("使用lambda表达式", System.out::println);- 说明:
::是方法引用符;lambda 推导时我们使用自己重写的方法,而传递方法引用可以让我们使用已有的方法;
-
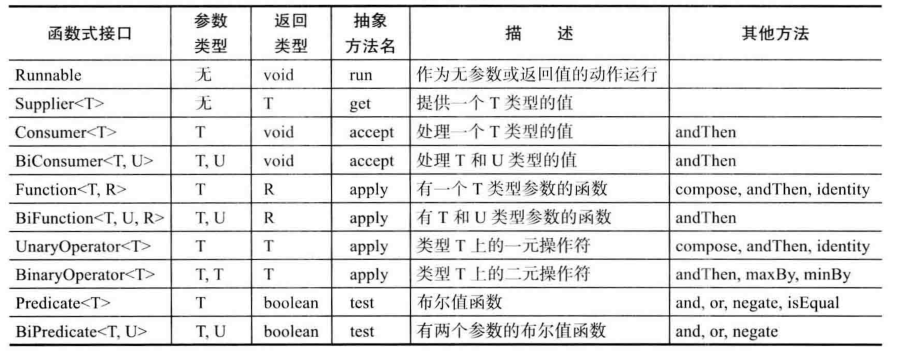
常用函数式接口
java.util.function包下
Stream 流
- 获取流:
- Collection 集合通过默认方法 stream() 获取;
- 数组通过
Stream.of()或Arrays.stream()方法获取; - Map 要将 keyValue 封装成 entry 再调用 stream() 方法获取;
- 流的操作分为两种:中间操作、终结操作,中间操作返回流本身,终结操作返回一个集合或值。
- 返回值不为 Stream 即会终结流;
| 方法 | 描述 |
|---|---|
void forEach(Consumer<? super T> action) | 将流中每一个元素交给 Consumer 处理 |
long count() | 返回流中元素个数 |
Stream<T> filter(Predicate<? super T> predicate) | 接受 Predicate 作为筛选条件,返回 true 则保留元素,否则剔除元素 |
Stream<R> map(Function<? super T, ? extends R> mapper) | 将 T 类型转换为 R 类型 |
Stream<T> limit(long maxSize) | 保留前几个元素 |
Stream<T> skip(long n) | 删除前几个元素 |
Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b) | 合并流 |