Overview
对象的创建包括 new、反射、克隆、反序列化这几种方式,下面主要讨论使用 new 对象的过程,以及对象的内存结构。知道了对象的内存结构,就可以知道一个对象在内存中占据的大小。
对象的创建
**总结:**分配内存 → 初始化(包括赋“零”值,设置头信息)→ 引用入栈 → 构造函数。
当 JVM 遇到 new 指令时,首先会在常量池中寻找,看有没有这个类的符号引用,没有找到即不合法、不存在;然后查看该类有没有被加载过,若没有,则必须先执行类的加载过程。
在类加载的过程中就会确定该类的对象所需的内存块大小,为对象分配内存的过程就是从堆中划分出一个相应大小的内存块,多线程环境下这个划分操作必须保证原子性。JVM 使用 CAS 加失败重试的方法保证其原子性。还有一种操作叫做 TLAB 分配,即为每个线程分配一个 本地线程分配缓冲(Thread Local Allocation Buffer,TLAB),每个线程创建对象时直接使用自己的 TLAB,避免了多线程同时操作堆中的同一片区域,但当一个线程的 TLAB 不够用而去再申请一块新的 TLAB 时,还是采取 CAS。使用 -XX: +/-UseTLAB 参数设定是否启用 TLAB。
TLAB 是从堆中标记的一块专门给某线程创建对象的区域,本质还是在堆中,只是在分配上是线程私有,使用上还是和堆一样,线程共享。具体可参考此处
分配完内存,JVM 要将该对象的实例数据部分初始化为**“零”值**,即在类中不需要赋值就能使用的默认值,如整形默认 0,浮点型默认 0.0,boolean 默认 flase,String 默认空串“ ”,引用型默认为 null……
赋“零”值完了之后,还要对对象头的信息进行设置,对象头包含了关于该对象的一些描述信息,如它是谁的实例,如何找到对应的元数据信息,GC 分代信息……
完成上述之后,将对象的引用入栈,最后才真正开始运行到我们写的 Java 代码,即执行构造函数。
对象的内存结构
对象的内存结构可以分为三部分:对象头、实例数据、对齐填充。
- 对象头 包含下面这几部分信息:
- 第一部分称为**“Mark Word”,用于存储对象自身的运行时数据,如哈希码(HashCode)、GC 分代年龄、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳等,它的 大小**和虚拟机的位数相同;
- 第二部分是**“Klass Word”,用于存储 类型指针**——一个指向该对象的 元数据 信息的 OOPs,它的大小要根据是否开启了指针压缩来判断;
- 元数据(不是 Class 对象),即我们常说的存在于方法区(元空间)的类加载过程中从 class 文件中提取出来的的类结构信息,如类中包含的变量名、方法名、方法执行的代码……
- 如果是数组,还会有一部分信息用于记录数组的长度。
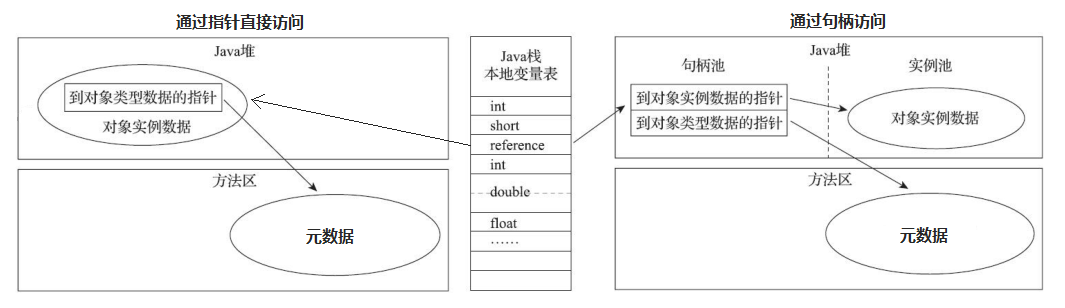
有无类型指针取决于具体虚拟机的实现,寻找元数据并不一定要非要经过对象头中的类型指针,如使用句柄访问对象,句柄中除了包含对象实例的指针,还包括指向该对象的元数据的指针,这时就不必在对象头中添加类型指针。具体可参照下图:
- 实例数据部分,存储我们代码中定义的成员,包括从父类继承下来的。
- 存储顺序受到两方面影响:
- 一方面是虚拟机分配策略(参数:-XX:FieldsAllocationStyle),默认分配顺序是 longs/doubles、ints、shorts/chars、bytes/booleans、oops(Ordinary
Object Pointers,OOPs),即按照所占内存空间从大到小分配空间; - 另一方面受到成员在代码中定义的顺序影响,且 父类成员会被分配在子类之前。
- 一方面是虚拟机分配策略(参数:-XX:FieldsAllocationStyle),默认分配顺序是 longs/doubles、ints、shorts/chars、bytes/booleans、oops(Ordinary
- 存储顺序受到两方面影响:
- 对齐填充,即将对象内存大小填充到 8 字节 的整数倍,方便虚拟机寻址。
对象所占内存的计算
- 知道了对象的内存结构,很容易可以知道:
对象(obj) = 对象头(Header) + 实例数据(Data) + 对齐填充(Padding)
- Data 和 Padding 比较好计算,最关键的一部分就是 Header 的大小:
Header = MarkWord + KlassWord(若有) + 描述数组长度的数据(若有)
- HotSpot 虚拟机采用通过指针直接访问的方式寻找对象,所以它有 KlassWord,我们计算时需要加上 KlassWord。MarkWord 大小与 VM 的位数相同,KlassWord 存储的是一个类型指针,它又是多大?这就得了解一下 指针压缩(compressed oops) 的概念:
指针压缩
指针压缩在 JVM 中就是将 64bit 的指针压缩为 32bit,是针对 64 位 VM 而言的。
- 为何压缩
程序里面到处都是指针引用,不压缩占内存,这也是为什么相同软件 64 位比 32 位大一点;不仅指针变 ” 大 ” 了,而且与其相关的操作代价也变大了,比如内存中维护的一些表就要变大。
- 怎么压缩
压缩成 32bit 的前提是:堆内存要在 32GB 以下。
32 位按字可寻址范围为 232=4GB,回想对齐填充中说的,对象都是按 8 字节补齐,也就是说对象的地址末三位都是 0,这意味着什么,可以省略掉末三位,就像表示浮点数时省略个位的“ 1 ”一样,取值的时候再左移三位即可恢复。
即我们现在的最大可寻址范围为 232+3=32GB,超过了 32GB 就不行了,可以理解为没压缩前按单字寻址,压缩后按“8 字”寻址。
-
对象头大小
现在就知道了 非数组 的对象头的大小:
MarkWord + KlassWord- 32 位 VM:32+32 = 64 bit = 8 Byte;
- 64 位 VM(不压缩指针):64+64 = 128 bit = 16 Byte;
- 64 位 VM(压缩指针):64+32 = 98 bit = 12 Byte;
数组 的对象头的大小:再加上 4 Byte 的描述数组长度的信息。
-
其他
- 对象中的引用型属性,只是一个引用,根据是否开启了指针压缩,为 4 或 8 Byte。
- 静态属性属于类,不做计算。
计算对象大小
环境:JDK1.8、64 位
即 Header 大小为:12Byte 或 16Byte(含数组);
使用 jol 工具类分析对象大小:
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.17</version>
</dependency>import org.openjdk.jol.info.ClassLayout;
public class ObjectLayoutTest {
public static void main(String[] args) {
System.out.println(ClassLayout.parseInstance(new Son()).toPrintable());
}
}
class Father { private int fInt; }
class Son extends Father { private int sInt; private long sonL; }- 默认开启指针压缩:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0xf800c181
12 4 int Father.fInt 0
16 8 long Son.sonL 0
24 4 int Son.sInt 0
28 4 (object alignment gap)
Instance size: 32 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total- 通过参数
-XX:-UseCompressedOops关闭指针压缩:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 8 (object header: class) 0x0000000025df4be8
16 4 int Father.fInt 0
20 4 (alignment/padding gap) 注意此处,父子属性之间可能有填充!
24 8 long Son.sonL 0
32 4 int Son.sInt 0
36 4 (object alignment gap)
Instance size: 40 bytes
Space losses: 4 bytes internal + 4 bytes external = 8 bytes total如果包含引用、数组类型,则保存的都是引用,如下示例(默认开启指针压缩):
class Father { private int fInt; }
class Son extends Father {private long sL; private Long sLong; private Father f; private Father[] fArray;}ClassLayout.parseInstance(new Son()).toPrintable()将打印:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0xf800c181
12 4 int Father.fInt 0
16 8 long Son.sL 0
24 4 java.lang.Long Son.sLong null
28 4 site.henrykang.Father Son.f null
32 4 site.henrykang.Father[] Son.fArray null
36 4 (object alignment gap)
Instance size: 40 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes totalClassLayout.parseInstance(new Son[]{new Son()}).toPrintable()将打印:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0xf800c205
12 4 (array length) 1
16 4 site.henrykang.Son Son;.<elements> N/A
20 4 (object alignment gap)
Instance size: 24 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total