Overview
数据库表的设计简单可以分为这几个步骤:需求分析,提取需求中的实体、属性以及关系;逻辑结构设计,将需求分析的结果提取成独立的 关系模式,形成 E-R 图;最后将 E-R 图转换为数据库关系模型。其中关系模式的 规范化程度,直接影响到我们数据库的稳定性,合理的关系模式可以避免数据的冗余,避免发生插入、删除、修改等异常。
一些概念
- 码
- 超码:在一个元组中,能够唯一确定该元组的属性组;
- 候选码:候选码是**”最小“**的超码;
- 包含在候选码中的属性,称为 主属性,不包含在任何候选码中的属性称为 非主属性;
- 主码:若候选码多于一个,在其中选取一个作为主码;
- 依赖
- X→Y 称为 Y 依赖于 X,X 称为 决定因素,所以也可以说 X 决定 Y;
- 若 X→Y,且 X 的任何一个真子集 X ‘ 都有 X ‘-/→ Y,称 Y 完全依赖于 X;
- 否则称为 Y 部分依赖于 X;
- 若 X→Y,Y→Z,而 X-/→Y 则称 Z 传递依赖 于 X;
- 范式(Nomal Form)
- 描述关系模式的规范化程度的式子,称为 范式,级别越高则规范化程度越高,低级的范式可以通过关系分解形成若干高级的范式;
- 1NF:关系模式中的属性必须具有原子性;
- 2NF:在 1NF 前提下,非主属性必须完全依赖于任何一个候选码;
- 3NF:在 2NF 前提下,非主属性不能传递依赖于码;
- BCNF:在 1NF 前提下,每一个决定因素都包含码;可以推出满足 2、3NF:
- 还有 4NF、5NF 都比较复杂,一般数据库表满足 3NF 就比较合理了。
范式
-
设有如下独立的关系模式:
- 学生:student(stu_id,stu_name ……)
- 校园卡:card(card_id,card_pwd ……)
- 课程:course(c_id,c_name,c_desc ……)
- 成绩单:sc(stu_id,c_id,grade ……)
- 部门:dept(d_id,d_name,d_desc ……)
-
2NF:在 1NF 前提下,非主属性必须完全依赖于任何一个候选码;不满足 2 NF 就可能出现以下异常:
- 插入异常:将学生和成绩单合并成新的关系模式 student+sc(stu_id,c_id,stu_name,grade ……),其中非主属性 stu_name 部分依赖与码,即不符合 2NF,当插入一个学生而他还没有选课时,就无法插入,因为主码缺少一个属性 c_id;
- 删除异常:还是上面的 student+sc 关系模式,当某学生退课时,会连同该学生的信息都被删除;
- 更新异常:假设学生改名了,而他选了 n 门课,表中就有 n 条记录,不仅数据冗余,而且还要保证所有的姓名都修改,倘若其中一条修改失败,就会导致数据不一致性;
-
3NF:在 2NF 前提下,非主属性不能传递依赖于码;即在 2NF 的基础上,消除了非主属性对码的传递依赖;考虑 student+dept(stu_id,stu_name,d_name,d_desc),d_desc 传递依赖于 stu_id,不符合 3NF,同样会发生上面三种异常:
- 插入异常:想插入一个新的部门,至少得有一个学生才行;
- 更新异常:冗余,更新 d_desc 需要更新每个学生的 d_desc;
- 删除异常:例子没举好,非要说的话可以和上面一样,删除 d_desc 需要在每一个 student 记录中都删除;
-
BCNF:在 1NF 前提下,每一个决定因素都包含码;消灭了 3NF 中可能存在的主属性对码的部分依赖和传递依赖;
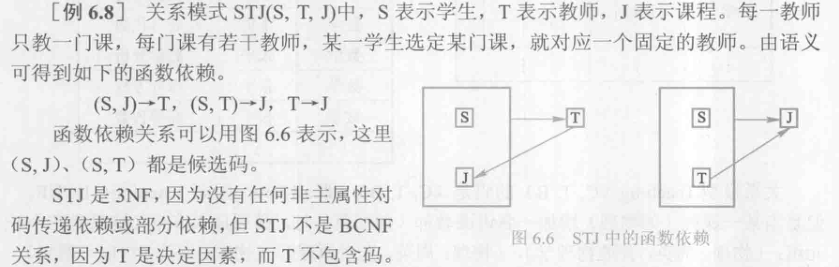
- 由此也可以看出为什么我们一般满足 3NF 即可,因为 BCNF 消除了主属性对码的部分和传递依赖,而一般我们的表中主码元组中只有一个属性,就不会发生主属性对码的依赖;
E-R 图转化为数据库模型
E-R 图的实体就是表,属性就是表的字段,主要解决的问题是关系的处理:
- 1:1 关系,如学生和校园卡是一对一的关系,通常进行合并,也可以将一方的主键作为属性加到另一方中;
- 1:n 关系,如学生和部门是一对多的关系,可以合并(会冗余),但通常将 1 方的主键作为属性加到 n 方中;
- m:n 关系,如学生和课程是多对多关系,需要提取一个中间关系 sc,m、n 两方的主键作为属性加入其中;
- 三个或以上关系,同 m:n;