Scala 是一个基于 JVM 的多范式 (面向对象 + 函数式编程) 的编程语言。
Hello Scala
配置 SCALA_HOME 与 Path 后使用 scala -version 验证,使用 IDEA 创建一个 scala 模块。
/*
* scala 中一切皆对象
* object 关键字用于声明一个单例对象
* 静态方法通过`对象名.方法名`来调用
* def 关键字用于声明一个方法
* 变量名声明在前,类型声明在后,使用`:`隔开
* Unit 等同于 Java 中的 Void
* scala 中可以调用部分 Java 类库
* println 引用的就是 System.out.println
* 行末的`;`可以省略
*
* */
object HelloScala {
private val helloMsg = "Hello Scala !"
private def sayHello(msg: String): Unit = {
println(msg)
}
def main(args: Array[String]): Unit = {
sayHello(helloMsg)
}
}编译后会生成两个 class 文件,其中一个以 $ 结尾,它们共同组成了这个 Scala 对象,反编译代码如下:
// HelloScala.class
public final class HelloScala
{
public static void main(final String[] args) {
// 通过 HelloScala$ 中的静态对象 MODULE$ 调用 HelloScala$ 中的 main 方法
HelloScala$.MODULE$.main(args);
}
}
// HelloScala$.class
public final class HelloScala$
{
// 单例对象的引用
public static HelloScala$ MODULE$;
private final String helloMsg;
// 创建单例对象
static {
new HelloScala$();
}
// getter 访问器
private String helloMsg() {
return this.helloMsg;
}
// 成员方法
private void sayHello(final String msg) {
Predef$.MODULE$.println((Object)msg);
}
// main 方法
public void main(final String[] args) {
this.sayHello(this.helloMsg());
}
// 构造方法
private HelloScala$() {
HelloScala$.MODULE$ = this;
this.helloMsg = "Hello Scala !";
}
}变量与类型
Scala 是一个强类型语言,但当类型可以被推断出来时,可以省略类型声明,编译器会自动添加。
var name: String = "变量"
// 自动推断类型
var name = "变量"
// val 声明一个常量,由编译器进行检查,编译后实际上没有区别,没有 final 关键字
val name = "常量"变量命名规范与 Java 类似,不能以数字开头,可包含字母、数字、下划线、美元符,特别的可以使用大部分特殊字符作为变量名 (编译时会自动转换为 Java 兼容的变量名)。
var + = "xxx"
var - = "xxx"
var * = "xxx"
var / = "xxx"
// ...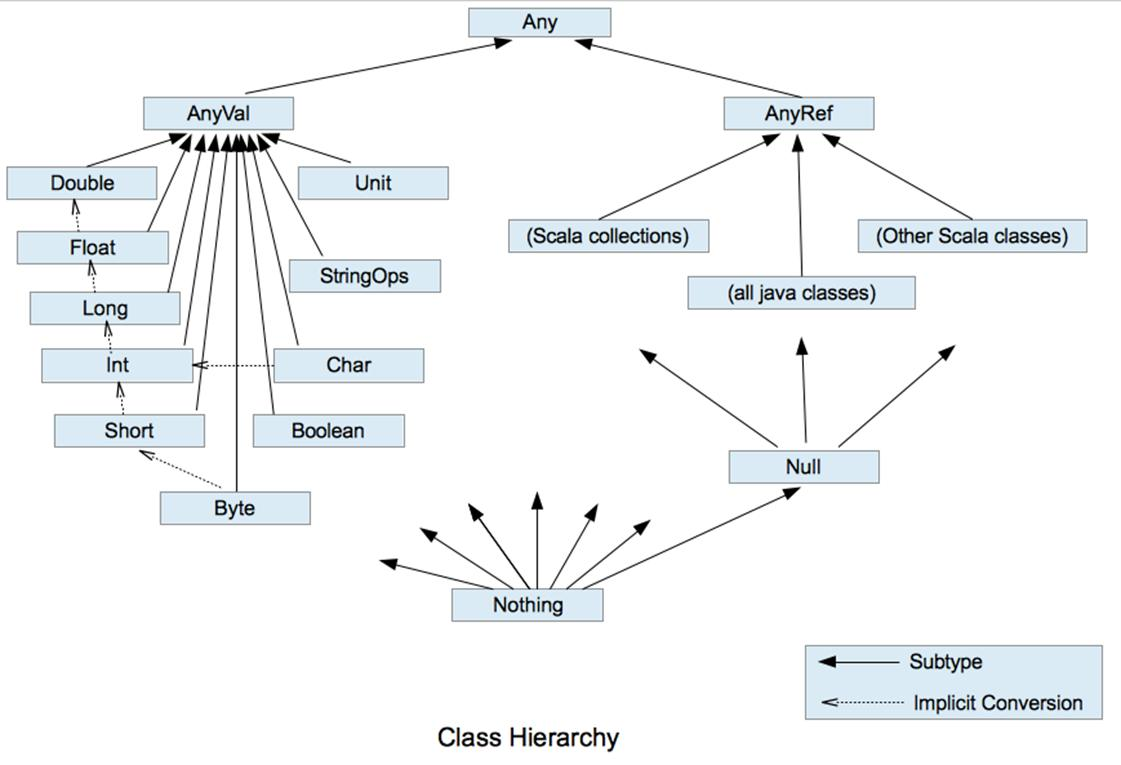
图中实线表示继承,虚线表示隐式转换,Any 是所有类的父类,AnyVal 值类型,AnyRef 引用类型。
Unit、Null、Nothing
- Unit: 类似于 Java 中的 Void,只有一个实例
(); - Null: 空引用,只能赋给引用类型,只有一个实例
null; - Nothing: 是所有类的子类,表示什么也不是,作为返回值时表示什么也没返回;
类型转换
浮点数默认为 Double,整形默认为 Int,低精度与高精度运算时,自动转换为高精度。
强制类型转换使用 toXxx(),注意只对最近的操作数有效,无参方法可以省略小括号:
val num1: Int = 1 + 10 * 1.5.toInt // 11
val num2: Int = (1 + 10 * 1.5).toInt // 16数字与字符串转换:
// 转字符串
val s1: String = 1.5.toString
// 转数字
val s2 = "1.5"
println(s2.toFloat)
println(s2.toInt) // 报错,注意:浮点数字符串转整形时,不会自动截断字符串
Scala 中的 String 就是 java.lang.String,可以使用插值表达式和多行字符串。
// 插值表达式
var name = "zhangsan "
println(s"name=${name.trim()}")
// 多行字符串,多用于 sql 与 json 拼接,其中的 `|` 表示顶格符
var tableName = "tableName"
println(
s"""
|select *
| from ${tableName}
| where 1 = 1
|""".stripMargin)
// 字符串乘 * 操作,表示重复
println("123" * 3) // 123123123== 与 eq
Scala 中 a eq b 比较的是 a 与 b 的内存地址;而 a == b 调用的是 equals 方法,当任一个为 null 时返回 false,都为 null 时返回 true
流程控制
if else
if else 语法与 Java 中的一样,特别的 Scala 中没有三目运算符 ? :,使用 if else 代替。
val a = 10
val b = 20
val c = if(a > b) a else b
println(c) // 20
// 赋值语句还可以这样写
val d =
if(c > 20){
"结果大于 20"
}
println("d=" + d) // d=(), 即 Unitfor
Scala 中的 for 循环语法与 Java 中有一定区别。
<-、to与until关键字
// 左闭右闭
for(i <- 1 to 3) {
println(s"i=${i}") // 1 2 3
}
// 左闭右开
for(i <- 1 until 3) {
println(s"i=${i}") // 1 2
}
// 遍历 list
var list = List("Hello", "Scala")
for (item <- list) {
print(item + " ") // Hello Scala
}- 倒序遍历
for(i <- 1 to 3 reverse) {
println(s"i=${i}") // 3 2 1
}- 步长控制
// 控制步长
for (i <- Range(1, 10, 2)) {
println(s"i=${i}") // 1 3 5 7 9
}
for (i <- 1 to 10 by 2) {
println(s"i=${i}") // 1 3 5 7 9
}- 添加 filter
// 添加过滤条件
for (i <- 1 to 10 if i % 2 != 0) {
println(s"i=${i}") // 1 3 5 7 9
}- 添加变量
// 添加运算逻辑
for (i <- 1 to 3; j = i + 1) {
println(s"i=${i};j=${j}")
}
// 小括号可以换为中括号
for {
i <- 1 to 3
j = i + 1
} {
println(s"i=${i};j=${j}")
}- 使用 yield 关键字处理数据
// 使用 yield 关键字循环处理数据,类似于 Java Stream.map()
val res = for(i <- 1 to 10) yield {
if (i % 2 == 0) {
"偶"
} else {
"奇"
}
}
println(res) // Vector(奇, 偶, 奇, 偶, 奇, 偶, 奇, 偶, 奇, 偶)while
while 与 do while 语法与 Java 类似。
跳出循环 Breakable
Scala 中 没有 break 和 continue 关键字来跳出循环,而是使用更加面向对象的 breakable 实现。
下面的代码通过 filter 模拟 continue 和 break,可以看得出来即便没有这两个关键字,也可以实现相同的逻辑,所以 Scala 中舍弃了不够面向对象的 break 和 continue。
// 使用 filter 实现 continue
for (i <- 1 to 10 if (i != 2 && i != 3)) {
println("i=" + i)
}
// 使用一个 flag 实现 break
// 注意满足 break 条件后,还是会遍历完集合中的剩余元素
var isContinue = true
for (i <- 1 to 10 if isContinue) {
println(s"i=${i}") // 1 2 3
if(i > 2) isContinue = false
}使用 breakable:
Breaks.breakable {
for (i <- 1 to 10) {
if (i == 5) {
Breaks.break()
}
println(s"i=${i}")
}
}
// 使用静态导入简写
import scala.util.control.Breaks._
breakable {
for (i <- 1 to 10) {
if (i == 5) {
// 这里不是关键字,而是在方法或函数没有参数时,调用可以省略 ()
break
}
println(s"i=${i}")
}
}进入 breakable 方法查看其源码,本质是利用了异常处理:
// break 直接抛了一个异常
def break(): Nothing = { throw breakException }
// breakable 的参数接收一段代码逻辑 op;
// 竟然能够传递一段代码逻辑,更加应证了 scala 中一切皆对象
def breakable(op: => Unit) {
try {
op
} catch {
case ex: BreakControl =>
// 如果捕捉到了 break 异常,就什么也不做,否则抛出,实现了打破循环
if (ex ne breakException) throw ex
}
}switch
Scala 中使用 模式匹配 实现 switch。
函数式编程
函数 与 方法 都能够封装一段功能逻辑,区别在于方法属于对象的一个成员,存在重载、重写等语义,通过对象引用调用;而函数可以被直接调用,Scala 中的函数编译后就是一个类的静态方法。
object HelloScala {
def main(args: Array[String]): Unit = {
// main 中定义的一个函数
def sayHello(): Unit = {
println("Hello 函数!")
}
sayHello()
this.sayHello()
}
// HelloScala 对象的方法
def sayHello(): Unit = {
println("Hello 方法!")
}
}- 可变参数、默认值、具名参数
// 可变参数,只能放在形参列表最后
def test(a: String, b: String*): String = {
return s"${a} ${b.mkString}"
}
println(test("Hello", "S", "c", "a", "l", "a")) // Hello Scala
// 默认值
def test2(a: String, b: Int = 18): String = {
return s"${a} ${b}"
}
println(test2("Hello")) // Hello 18
// 当默认值不在最后一个时,使用具名参数传值
def test3(a: String = "Hello", b: String): String = {
return s"${a} ${b}"
}
println(test3(b="Scala")) // Hello Scala语法糖简化
Scala 中有很多简化规则:
- 省略
return,Scala 会使用函数体的最后一行代码作为返回值; - 省略
{},当函数体只有一行代码时; - 省略
:和返回类型,当返回类型能够被推断时; - 省略
=,当返回类型为 Unit 时; - 如果声明了返回类型为 Unit,那么即便使用了 return ,返回结果也会被丢弃;
- 省略
(),当声明或调用无参函数时; - 特别的,当声明函数时省略了小括号,则调用时也不能写小括号;
- 省略
def,当只关心处理逻辑而不关心名称时,其实就是匿名函数,像 breakable 中接收的参数就是该场景;
// 0.完全体不省略
def fun0(s: String): String = {
return s + "123"
}
// 1.省略 `return`,Scala 会使用函数体的最后一行代码作为返回值;
def fun1(s: String): String = {
s + "123"
}
// 2.省略 `{}`,当函数体只有一行代码时;
def fun2(s: String): String = s + "123"
// 3.省略 `:` 和 `返回类型`,当返回类型能够被推断时;
def fun3(s: String) = s + "123"
// 4.省略 `=`,当返回类型为 Unit 时;
def fun4(s: String) {
println(s + "123")
}
// 5.如果声明了返回类型为 Unit,那么即便使用了 return ,返回结果也会被丢弃;
def fun5(s: String): Unit = {
return s + "123" // 返回 Unit,println(fun5("0")) 打印为 `()`
}
// 6.省略 `()`,当声明或调用无参函数时;
def fun6: String = "123"
println(fun6) // 编译正常
println(fun6()) // 编译报错,当声明函数时省略了小括号,则调用时也不能写小括号;
// 7.省略 `def`,当只关心处理逻辑而不关心名称时
// fun7 接收一个函数作为参数,并且调用了该函数,相当于 callback 函数
def fun7(op: (Int, Int) => Int) = println("fun7: " + op(10, 10))
def fun7_op_plus(a: Int, b: Int): Int = a + b
def fun7_op_minus(a: Int, b: Int): Int = a - b
fun7(fun7_op_plus)
fun7(fun7_op_minus)
// 直接将函数过程作为参数匿名传递
fun7((a: Int, b: Int) => a + b)
// 如果匿名函数的参数可以被推倒,并且只会按顺序调用一次,那么可以用 _ 代替
fun7(_ + _)
// 函数调用时 () 可以使用 {} 代替,就像前面提到的 breakable 一样
def fun8(op: => Double) = println(op)
fun8 {
Math.random()
}函数对象
Scala 中函数也是对象,可以作为变量、函数参数、函数返回值。
函数的参数个数没有限制,但是函数作为对象时,参数最多 22 个。
// 1. 在函数后加上 `_` 可以将函数作为引用传递
def fun1() = println("fun1")
var fun1_1 = fun1 _
fun1_1()
// 2. 如果变量类型声明明确,那么可以不使用 _
/*
* 注意如果声明 fun1 时不带 (),则此处 () 会报错,应写为
* var fun1_2: () => Unit = fun1 _
* 原因是编译器无法推测出是想要调用 fun1 还是传递 fun1
* */
var fun1_2: () => Unit = fun1
fun1_2()
// 3. 函数作为参数
def fun2(cb: => Unit) = cb
def fun2_cb = println("cb")
fun2(fun2_cb)
fun2(println("cb"))
// 4. 函数作为返回值
def fun3() = {
def fun4() = {
}
fun4 _
}
val fun5 = fun3()
// 调用
fun5()
// 等价于
fun3()()补充
闭包
如果一个函数访问了一个外部局部变量,并且改变了这个局部变量的生命周期,那么这个函数所处的作用域称为闭包。
在 Java 中匿名内部类只能访问局部的 final 对象,就是因为局部变量与内部类实例生命周期不一致的缘故。
public class OuterClass {
private String outerFiled = "outerFiled";
// 方法结束时,方法中的局部变量就弹栈了
public Runnable createRunnable() {
final String finalVariable = "I'm final";
String nonFinalVariable = "";
nonFinalVariable = "I'm not final";
return () -> {
System.out.println(finalVariable);
// 下面这行会报错,因为匿名内部类试图访问一个非 final 的局部变量
// System.out.println(nonFinalVariable);
// 这里不会报错是因为匿名内部类实例持有外部类实例的引用,
// 匿名实例释放之前,外部类实例不会被释放
outerFiled = "xxx";
System.out.println(outerFiled);
};
}
}与 Java 不同的是,Scala 可以捕获外部的非 final 局部变量,这是因为编译器进行了特殊的处理,它会将这个局部变量包含在一个对象中,匿名函数再通过这个对象引用该外部变量,相当于上面 Java 代码中的引用 OuterClass 的成员变量。
// 匿名函数引用了 fun 函数的局部变量 x,匿名函数的作用域组成了一个闭包
def fun(x: Int) = (y: Int) => x + y柯里化
将函数的参数列表分离成多个参数列表,称为函数柯里化。这只是一个语法规则,编译后还是一个正常的方法。
def funC(a: Int)(b: Int): Int = a + b;
println(funC(1)(1)) // 打印 2懒加载
当函数的调用被声明为 lazy 时,函数将被延迟直到我们首次访问才真正执行。
object TestLazy {
def main(args: Array[String]): Unit = {
def fun = {
print("exec ")
"000 "
}
lazy val msg = fun
print("111 ")
print(msg)
print("222 ")
// 打印:111 exec 000 222
}
}面向对象
包
与 Java 不同,Scala 中的源文件存储位置不一定非得放在对应的包路径下,同一个源文件中也可以定义多个类、对象,且不需要定义与源文件名相同的类或对象。
包的命名以非数字开头的字母、数字、下划线和 . 组成;
除了使用 . 来表示包的层级关系,还可以使用嵌套风格:
package site.henrykang.scala
// 等同于
package site
package henrykang
package scala
// 嵌套风格
package site {
package henrykang {
package scala {
}
}
}包的导入规则:
- 源文件顶部声明的 import,在这个文件中都可以使用;
- 局部 import,例如在对象或函数中导入,则只能在当前作用域内使用;
- 通配符导入:
import java.util._ - 所有源文件都默认导入
java.lang._、scala._、scala.Predef._; - 别名:
import java.util.{ArrayList=>JL} - 指定导入:
import java.util.{HashSet, ArrayList} - 屏蔽导入:
import java.util.{ArrayList =>_,_}(导入所有除了 ArrayList) - 绝对路径:import 时会先搜索子包中的类,如果没有,再从顶级包中依次搜索,进行导入,这时如果子包中有同名的类,可能会导致与期望不符,这就需要使用
_root_明确从顶级包中搜索导入;new _root_.java.util.HashMap()
包对象:
Scala 中可以在每个包下使用 package object 包名 定义一个与包同名的对象,称之为 包对象,当钱包和子包下所有的 class 和 object 都可以直接访问该对象,可用于共享变量、函数。
package object site {
val name: String = "site"
}
// 当前包
package site {
object Test {
def main(args: Array[String]): Unit = {
println(name)
}
}
}
// 子包
package site {
package henrykang {
object Test {
def main(args: Array[String]): Unit = {
println(name)
}
}
}
}类和对象
Scala 中的类声明与 Java 中有一些语法区别,见代码:
import scala.beans.BeanProperty
class Person {
// 定义 name 属性并赋初始值
var name: String = "zhangsan"
// 只声明不赋值会编译出错,否则就要声明为抽象类
// var age: Int
/*
* 使用`_`表示给属性一个对应类型的默认空值,要求必须声明类型
* 如果是 val 则声明时必须显示赋初值
* */
private var age: Int = _
/*
* Scala 默认生成的访问器与属性同名,即没有 get/set 前缀,
* 这样在使用一些框架时会存在兼容性问题,
* 使用 @BeanProperty 注解,编译后会追加生成对应属性的 getter 和 setter
* */
@BeanProperty var gender: String = "男"
// @BeanProperty 只能用于 non-private 否则编译会报错
@BeanProperty private var address: String = _ // 编译报错
}
// 与类同名的 object 称为其伴生对象
object Person {
def main(args: Array[String]): Unit = {
val person = new Person()
// 访问属性
println(person.name)
// 设置属性
person.gender = "男"
// 通过访问器访问
person.setGender("女")
println(person.getGender)
println(person getGender) // 省略 .
}
}
// 注意:Scala 中对属性的访问本质上都是通过访问器访问,
// 反编译生成的 gender 属性访问器如下
// ...
public String gender() {
return this.gender;
}
// person.gender = "男" 实际调用的就是该方法
public void gender_$eq(final String x$1) {
this.gender = x$1;
}
public String getGender() {
return this.gender();
}
public void setGender(final String x$1) {
this.gender_$eq(x$1);
}
// ...访问权限
Scala 中没有 public 访问修饰符,默认访问权限就是 public。
Java 中的访问权限:
| 作用域与可见性 | 当前类 | 同包类 + 子类 | 不同包子类 | 其他 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | x |
| default | √ | √ | x | x |
| private | √ | x | x | x |
Scala 中的访问权限:
| 作用域与可见性 | 当前类 + 伴生 | 同包类 | 子类 | 其他 |
|---|---|---|---|---|
| 默认 | √ | √ | √ | √ |
| protected | √ | x | √ | x |
| private | √ | x | x | x |
| private[包名] | √ | √ | √ | x |
注意:
- Scala 中的 protected 比 Java 中的更加严格,只有当前类与子类可以访问;
private[包名]称为包私有,可以指定当前类的的包或其父包,被修饰的成员可以被该包及其子包下的类访问。
构造函数
Scala 中的构造器包含主构造器和辅助构造器。
object TestConstructor {
def main(args: Array[String]): Unit = {
val test = new Test("a", "b", "c")
println(test.a + test.b + test.c) // 主构造器执行了 辅助构造器执行了 abc
}
class Test(_a: String, _b: String) { // 主构造器
var a: String = _a
var b: String = _b
var c: String = _
// 辅助构造器,可以有多个,根据重载的规则进行匹配
def this(_a: String, _b: String, _c: String) {
// 必须调用主构造器
this(_a, _b)
c = _c
println("辅助构造器执行了")
}
println("主构造器执行了")
}
}特别的,当主构造器无参数时,可以省略 (),当主构造器的参数使用 var 或 val 修饰时,则该参数将不再只是局部参数,而是类的成员。
伴生对象
伴生类可以通过 伴生对象名.成员名 直接访问伴生对象的私有成员,伴生对象中也可以通过半生类的实例访问其私有成员。
抽象类也可以有伴生对象,可以访问伴生对象的成员,但由于抽象类无法实例化,不存在伴生对象访问抽象类实例的情况。
伴生类必须和伴生对象在同一个源文件中定义。
伴生对象弥补了 Scala 中没有 static 的问题,定义在伴生对象中的成员,通过半生对象名调用,就像是 Java 中的静态调用。
伴生对象中有一个特殊的 apply 方法,用于构造并返回一个伴生类的实例,且调用时可以省略方法名。
object TestApply {
// 使用 private 可以私有化主构造方法
class Person private {
var name: String = _
}
object Person {
def apply(name: String): Person = {
val person = new Person()
person.name = name
person
}
}
def main(args: Array[String]): Unit = {
// 报错显示无可用构造函数,因为被私有化了
// var p: Person = new Person("zhangsan")
// 只能通过伴生对象的 apply 方法创建
var p1: Person = Person.apply("zhangsan")
// 简化为
var p2: Person = Person("zhangsan")
}
}继承与多态
Scala 中的继承与 Java 一样,只能单继承,子类可以继承父类的成员属性和方法,父类构造器将先于子类构造器执行。
多态在代码层面的体现就是:1. 声明谁就只能调谁的方法;2. 创建谁就实际调用的谁的方法。
例如声明父类创建子类,就只能调用父类中声明的方法,不能调用子类特有的方法,但如果调用的是重写方法,那么执行的是子类的方法。
对于多态,特别的:
Java 中只有方法是动态绑定的,即声明父类创建子类对象,通过该对象访问父子类的同名属性,访问的其实是父类的属性;
Scala 中属性和方法都是动态绑定,本质是因为 Scala 中访问属性都是通过访问器进行的,而同名属性编译生成的访问器发生了重写,即产生了 Scala 属性也能发生多态的特性。
@Data
@EqualsAndHashCode(callSuper=false)
class Parent {
String msg = "parent";
}
@Data
@EqualsAndHashCode(callSuper=false)
class Child extends Parent {
String msg = "child";
}
public class Test {
public static void main(String[] args) {
Parent obj = new Child();
System.out.println(obj.msg); // parent,java 属性不会多态
System.out.println(obj.getMsg()); // child,重写的 get 方法发生了多态
}
}抽象类
Scala 中通过 abstract 关键字声明抽象类,抽象类中可以定义抽象属性和抽象方法。
子类继承父类,如果父类是抽象类,则子类需要重写父类中的抽象成员,否则子类也需要声明为抽象类,因为抽象意味着不完整,不完整的类是无法实例化对象的。
重写非抽象方法时,必须添加 overrid 关键字修饰,重写抽象方法时不需要,因为抽象方法存在的意义就是让子类重写。
abstract class Animal {
val msg: String
def say(): Unit = println(msg)
def walk(): Unit
// 声明一个变量
var var_a: String = ""
}
object Animal {
def main(args: Array[String]): Unit = {
val frog = new Frog()
frog.say()
frog.walk()
}
}
class Frog extends Animal {
// 重写 val
val msg: String = "gua~ gua~"
// 重写非抽象方法时,必须加 override 关键字
override def say(): Unit = println(msg + " !")
// 重写抽象方法,可以不加
def walk(): Unit = println("jump~")
// 编译报错,因为没必要重写变量,继承后直接使用即可
override var var_a: String = ""
}特质
Scala 中没有接口的概念,取而代之的是使用 trait 声明一个特质,特质拥有抽象类 + 接口的特性,实际编译后就会生成一个接口和一个实现该接口的抽象类。
一个类可以混入(继承/实现) 多个特质,创建对象时可以动态混入特质,动态混入的本质是创建了一个新的类混入该特质,然后创建该类的实例。
trait AnimalTrait {
// 常量
val msg: String
// 方法
def walk(): Unit
// 默认方法
def say(): Unit = println(msg)
}
trait Eat {
def eat(): Unit = println("我吃吃吃")
}
// 第一个特质使用 extends 连接,后面都使用 with
class Dog extends AnimalTrait with Eat {
override val msg: String = "汪汪汪"
override def walk(): Unit = println("跑跑跳跳")
}
class Person {
}
object HelloTrait {
def main(args: Array[String]): Unit = {
val dog = new Dog()
dog.eat()
// 创建对象时动态混入特质
val person = new Person() with Eat {}
person.eat()
}
}特质中的方法可以叠加,当混入的多个特质中有相同的方法声明时,则会出现方法冲突问题,叠加的调用顺序与混入的顺序相反,即最后混入的特质会先调用。
object TestTrait {
trait Laptop {
def desc = "笔记本电脑"
}
trait Memory extends Laptop {
override def desc = "32GB内存" + super.desc
}
trait Disk extends Laptop {
override def desc = "1T固态" + super.desc
}
class MyLaptop extends Memory with Disk {
override def desc = "我的笔记本是" + super.desc
}
def main(args: Array[String]): Unit = {
// 我的笔记本是1T固态32GB内存笔记本电脑
println(new MyLaptop().desc)
}
}其他
枚举
object Color extends Enumeration {
val RED = Value(1, "red")
val YELLOW = Value(2, "yellow")
val BLUE = Value(3, "blue")
def main(args: Array[String]): Unit = {
println(Color.RED)
println(Color.values)
}
}Type 别名
// 给 String 类起个别名 S
type S = String
var msg: S = "Hello"
def getMsg(): S = "Hello"异常处理
Scala 中没有受查异常,即任何时候都不强制 try-catch
// try-catch-finally
try {
var num = 1 / 0
} catch {
// 类似模式匹配
case ex: ArithmeticException => println(ex)
} finally {
println("finally")
}
// 使用 throws 注解表示会抛出何种异常
@throws(classOf[Exception])
// 使用 throw 抛出异常,返回结果为 Nothing
def test(): Nothing = {
throw new Exception("不对")
}泛型
在 Scala 中,泛型使用中括号 [T] 声明,有协变(Covariance)、逆变(Contravariance)以及上界(Upper bounds)、下界(Lower bounds)的概念。
协变、逆变
协变:如果 C[A] 是 C[B] 的子类型,且类型 A 是类型 B 的子类型,则我们称类型 C 是协变的,使用 [+T] 表示协变;
逆变:如果 C[A] 是 C[B] 的子类型,且类型 B 是类型 A 的子类型,则我们称类型 C 是逆变的,使用 [-T] 表示逆变;
def main(args: Array[String]): Unit = {
class Father {}
class Son extends Father {}
// 不变
class C1[T] {}
// 协变
class C2[+T] {}
// 逆变
class C3[-T] {}
// 编译报错,“不变”不具有继承关系
val c1: C1[Father] = new C1[Son]
// 编译正常,“协变”使得泛型也有了继承关系
val c2: C2[Father] = new C2[Son]
// 编译报错
val c3: C3[Father] = new C3[Son]
// 编译正常,“逆变”
val c4: C3[Son] = new C3[Father]
}上界、下界
上界:上界限定泛型类型变量只能是一个特定类型或者是这个类型的子类型,使用 [T <: C] 表示上界,相当于 Java 中的 <? extends T>;
下界:下界限定泛型类型变量只能是一个特定类型或者是这个类型的父类型,使用 [T >: C] 表示下界,相当于 Java 中的 <? super T>;
集合
Scala 中几乎所有集合都有可变(scala.collection.immutable) 和不可变(scala.collection.mutable) 两个版本,不可变是指调用相关方法不会改变原有集合,而是返回新的集合。
- 不可变集合
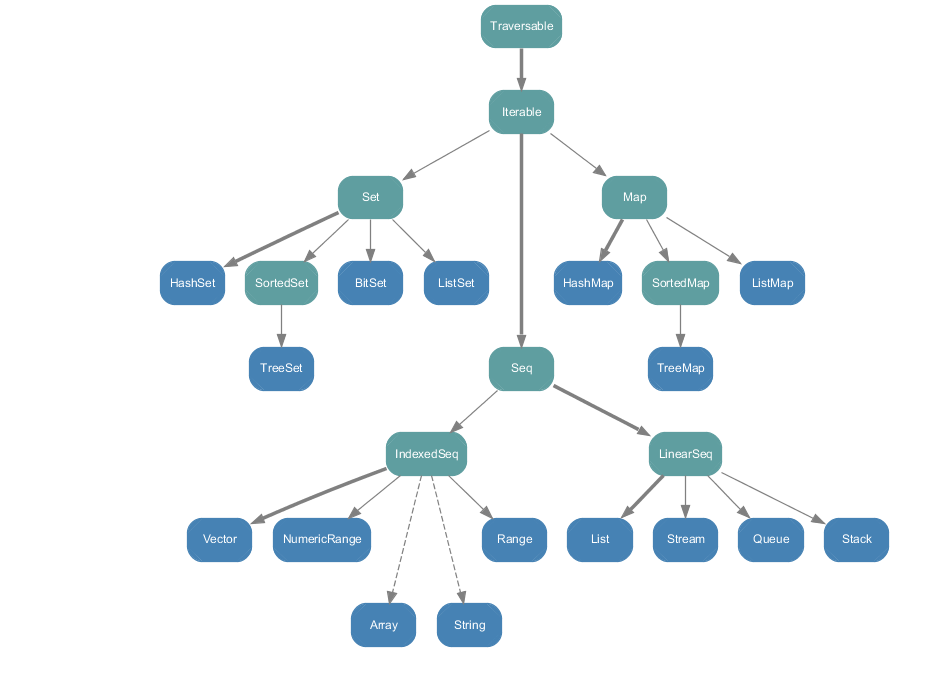
- 可变集合
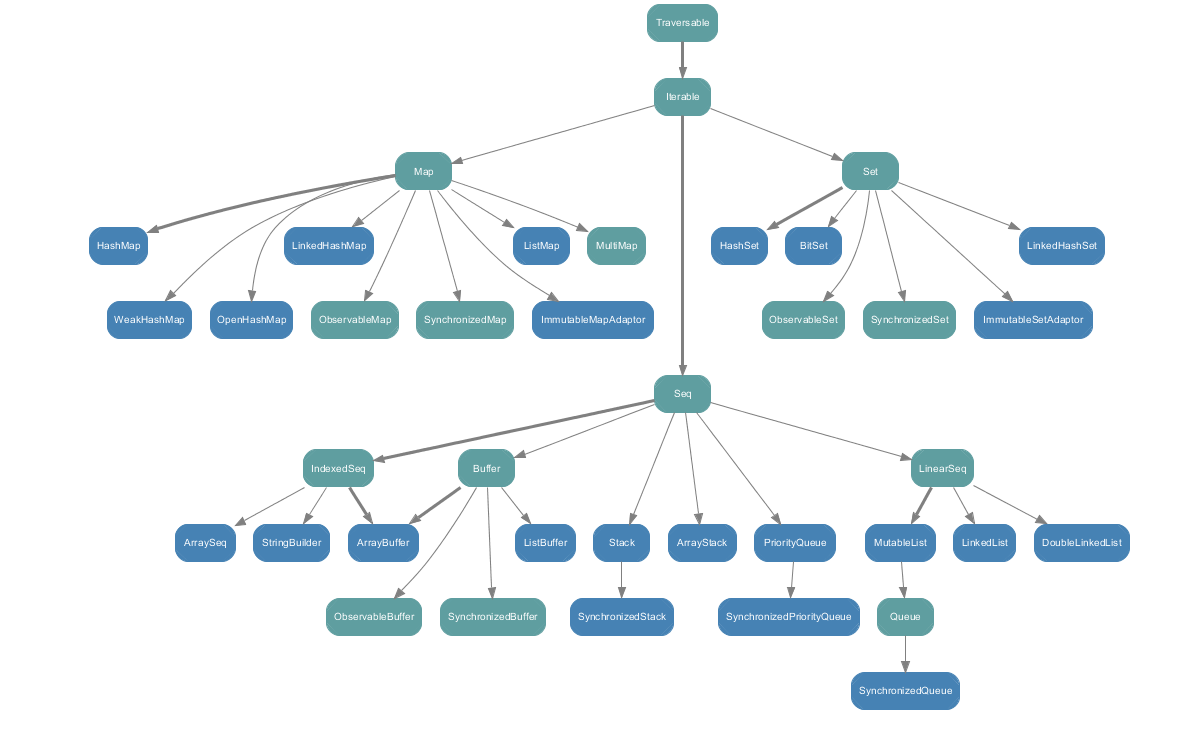
除了 Set、Map 是 Java 中也有的外,Seq 称为序列,Scala 中的 List 就继承自它,Seq 分为两大类 IndexedSeq 和 LinearSeq,前者适用于通过索引下标访问元素的情况,后者适用于遍历访问的情况,例如它提供了 head 和 tail 等操作。
可变集合大多命名是在对应不可变集合名称后加 Buffer;对于可变集合,可以使用 Synchronized 开头的集合。
Seq、Set、Map
参考
Array
Array 继承自 IndexedSeq,底层是 Java 数组。
- 定长数组 Array
// 声明一个有10个Int类型元素的数组
val arr = new Array[Int](10)
// 通过下标赋值
arr(0) = 1
// 通过下标访问
println(arr(1)) // 初始值 0
// 遍历
for(i <- arr) println(i)
// 通过 apply 方法创建
val arr1 = Array(1, 2, "3")- 变长数组 ArrayBuffer
/* 变长数组 */
val arrb = ArrayBuffer(1)
// 追加,append 接收变长元素
arrb.append(2, 3)
arrb += 4
// 指定位置插入
arrb.insert(0, 0)
// 追加数组
arrb ++= Array(5, 6)
// 在开头插入 -1
-1 +=: arrb
for (i <- arrb) print(i) // -1 0 1 2 3 4 5 6
// 相互转换
arr.toBuffer // 定长-->变长
arrb.toArray // 变长-->定长备注:+=、++=、+=:、++=: 等是至简原则省略 . 和 () 的方法调用,不是特殊运算符
- 多维数组
val arrd = Array.ofDim[Int](2, 2)
for (i <- arrd) {
for (j <- i) print(j)
println
}
// 打印
// 00
// 00Tuple
元组和函数对象的参数一样有最多 22 个的限制,只有两个元素的元组称为对偶元组,可以看作是一个 (k, v) 键值对,可用于当作 Map 的参数。
// 使用 () 声明元组,最多 22 个元素
val t1 = (1, "hello")
// 通过 _i 来访问元组中的元素,从 1 开始
println(t1._1)
println(t1._2)
// 通过 productElement 来访问元组中的元素,从 0 开始
println(t1.productElement(1))
// 遍历元组
for (i <- t1.productIterator) print(i)通用方法
基本
// 元素个数
println(list.length)
println(list.size)
// 是否为空
println(list.isEmpty)
// 反转
println(list.reverse)
// 去重
println(list.ditinct)
// join
println(list.mkString(", "))
// 遍历
list.foreach(println)获取元素
// 获取第一个元素
println(list(0))
println(list.head)
// 获取最后一个元素
println(list.last)
// 获取尾部元素 (除了第一个元素以外的元素)
println(list.tail)
// list.tail.tail... tails 用于返回一个迭代器
println(list.tails)
// 同理。获取首部元素 (除了最后一个元素以外的元素)
println(list.init)
println(list.inits)
// 获取指定个数的数据
println(list.take(3)) // 拿前 n 个
println(list.takeRight(3)) // 拿后 n 个
// 删除指定个数的数据
println(list.drop(3))
println(list.dropRight(3))
// 包含
println(list.contains(5))
// 查找满足条件的第一个元素
println(list.find(x => (x & 1) == 0)))交并差、切分、滑动、拉链
// 交集、并集、差集
println(list1.intersect(list2))
println(list1.union(list2))
println(list1.diff(list2))
// 切分,在第 n 个“位置”切
println(list.splitAt(1))
// 返回一个滑动窗口迭代器
list.sliding(窗口大小, 步长)
// 拉链:将两个集合中相同位置的数据拉取到一起,形成一个元组
// 注意,1.size取较小的那个;2.无序集合拉链的结果无法预期
println(list1.zip(list2))功能方法
map、filter、groupBy
// 映射,返回新集合
val list = List(1, 2, 3, 4)
println(list.map(_ * 2))
// 扁平化,相当于一对多映射
var list = List("Hello Scala", "!")
// flatten 为默认规则
println(list.flatten) // 输出 List(H, e, l, l, o, , S, c, a, l, a, !)
// 使用 flatMap 指定扁平化规则
println(list.flatMap(_.split(" "))) // 输出 List(Hello, Scala, !)
// 对键值对的值进行 map
var map = Map(("a", 1), ("b", 2))
println(map.mapValues(_ * 2))
// 过滤,保留偶数
val list = List(1, 2, 3, 4)
println(list.filter(x => (x & 1) == 0))
// 分组,根据奇偶分组,返回一个 Map
println(list.groupBy(x => (x & 1) == 0))
// 输出 Map(false -> List(1, 3), true -> List(2, 4))sortBy、sortWith
- 简单排序 sortBy
val list = List(1, 2, 3, 11, 22)
// 这里会有上下文界定隐式参数
// def sortBy[B](f: A => B)(implicit ord: Ordering[B]): Repr
// 默认升序
println(list.sortBy(item => item))
println(list.sortBy(item => item.toString))
// 降序排序
println(list.sortBy(item => item)(Ordering.Int.reverse))
/* 比较对象的单个属性 sortBy */
class User(val name: String, val age: Int, val weight: Double) {
override def toString: String = s"$name:$age:$weight"
}
val userList = List(
new User("aa", 18, 60),
new User("bb", 20, 65),
new User("cc", 22, 65),
new User("dd", 18, 65)
)
println(userList.sortBy(_.age))
println(userList.sortBy(_.age)(Ordering.Int.reverse))- 自定义排序 sortWith
/* 比较对象的多个属性 sortWith */
// 默认排序规则是升序,返回 true 表示 a < b
println(userList.sortWith((a, b) => a.age < b.age))
// 降序排序,只需要调个头
println(userList.sortWith((a, b) => a.age > b.age))
/* 比较对象的多个属性 sortWith */
println(
userList.sortWith((a, b) => {
// 先根据 age 排序
if (a.age == b.age) {
// 再根据 weight desc
a.weight > b.weight
} else {
a.age < b.age
}
})
)- Tuple 排序,用于简化多字段比较的情况
/* 上面的写法可以使用元组简化 */
println(
userList.sortBy(
user => {
// 使用 - 表示降序
(user.age, -user.weight)
}
)
)
println(
userList.sortBy(
user => {
(user.age, user.weight)
}
// 也可以通过参数指定排序规则
)(Ordering.Tuple2(Ordering.Int, Ordering.Double.reverse))
)reduce、fold
当需要对集合中的元素进行迭代计算时,使用 reduce,要求两个操作数和返回类型兼容;
迭代计算有方向,reduce 默认就是 reduceLeft。
val dataList = List(1, 2, 3, 4, 5)
println(dataList.reduce(_ - _)) // -13
println(dataList.reduceRight(_ - _)) // 3fold 与 reduce 类似,可添加一个集合外部的值,作为计算初始值。
val dataList = List(1, 2, 3, 4)
// 在首位添加:5 1 2 3 4
println(dataList.fold(5)(_ - _)) // -5
// 在尾部添加:1 2 3 4 5
println(dataList.foldRight(5)(_ - _)) // 3scan 与 fold 相同,区别在于返回计算的中间结果。
val dataList = List(1, 2, 3, 4)
println(dataList.scan(5)(_ - _)) // List(5, 4, 2, -1, -5)
println(dataList.scanRight(5)(_ - _)) // List(3, -2, 4, -1, 5)WordCount 案例
val dataList = List("Hello World", "Hello Java", "Hello Scala")
// 1
dataList.flatMap(_.split(" "))
.groupBy(x => x)
.mapValues(_.size)
.foreach(println) // (Hello,3)(World,1)(Java,1)(Scala,1)
// 2
dataList.flatMap(_.split(" "))
.map((_, 1)) // 转换为 tuple
.groupBy(_._1)
.mapValues(_.map(_._2).sum) // 对每一组List中的个数求和
.foreach(println)
// 3
dataList.flatMap(_.split(" "))
.map((_, 1))
.groupBy(_._1)
.mapValues(_.reduce((t1, t2) => (t1._1, t1._2 + t2._2))._2)模式匹配
Java 中的 switch case 存在穿透现象,如果不加 break 则匹配到满足条件的 case 后,后续的 case 不论是否匹配都会执行,没有 default 且没有匹配上也不会报错。
public static void main(String[] args) {
int a = 20;
switch (a) {
case 10:
System.out.println("10");
case 20:
System.out.println("20");
default: // default 可以写在任意位置,会最后匹配,但穿透时会按顺序调用
System.out.println("default");
case 30:
System.out.println("30");
}
}
// 输出 20 default 30Scala 中的 match 与 Java 不同,①没有穿透现象,②case _ => 相当于 default 放在第一行会直接执行,③如果没有匹配上,会报异常 scala.MatchError。
def main(args: Array[String]): Unit = {
val age = 10
age match {
case 10 => println("10")
case 20 => println("20")
case 30 => println("30")
case _ => println("other")
}
}匹配规则
匹配常量
def 匹配常量(x: Any) = x match {
case 5 => "Int five"
case "hello" => "String hello"
case true => "Boolean true"
case '+' => "Char +"
}匹配类型
def 匹配类型(x: Any) = x match {
case _: Int => "Int"
case _: Double => "Double"
case _: String => "String"
case _: Boolean => "Boolean"
case _: Char => "Char"
// 注意泛型擦除,List[_] 等价于 List[Any]
case _: List[_] => "List"
// 数组不存在擦除
case _: Array[Int] => "Array[Int]"
// 给默认情况起名 others,在方法体中引用
case others => "Any " + others
}匹配伴生对象、普通对象
- 匹配伴生对象
def 匹配伴生对象(x: Any) = x match {
case Int => "Int"
case Double => "Double"
// 注意 Scala 中没有 String,就没有 String 的伴生对象
// case String => "String"
case others => "Any " + others
}- 匹配普通对象 (unapply)
def main(args: Array[String]): Unit = {
val user: User = User("张三", 18)
val result = user match {
case User("张三", 18) => "yes"
case _ => "no"
}
println(result)
}
// 匹配普通对象
class User(val name: String, val age: Int) {}
object User {
def apply(name: String, age: Int): User = new User(name, age)
def unapply(user: User): Option[(String, Int)] = {
Some((user.name, user.age))
}
// 注意 unapply 不能重载
/*def unapply(user: User): Option[String] = {
Some(user.name)
}*/
}
// ---
// 当在 class 前声明 case 关键字表示 “样例类”,会自动生成对应的 unapply 方法
case class User(val name: String, val age: Int) {}匹配数组、列表
- 匹配数组
for (arr <- Array(
Array(0),
Array(1, 0),
Array(0, 1, 0),
Array(1, 1, 0),
Array(1, 1, 0, 1),
Array("hello", 90)
)) {
val result = arr match {
// 匹配 Array(0)
case Array(0) => "0"
// 匹配元素个数
case Array(x, y) => x + "," + y
// 匹配以 0 开头的数组
case Array(0, _*) => "以 0 开头的数组"
case _ => "something else"
}
println("result = " + result)
}- 匹配列表
// 和匹配数组很像
for (list <- Array(
List(0),
List(1, 0),
List(0, 0, 0),
List(1, 0, 0),
List(1)
)) {
val result = list match {
case List(0) => "0"
case List(x, y) => x + "," + y
case List(0, _*) => "0 ..."
case _ => "something else"
}
println(result)
}
// 特别的,匹配 :: 时要注意空集合
for (list <- Array(
List(1, 2, 3), // 1-2-List(3)
// 注意此处,相当于 1::2::Nil
List(1, 2), // 1-2-List()
List(1), // something else
)) {
val result = list match {
case first :: second :: rest => first + "-" + second + "-" + rest
case _ => "something else"
}
println(result)
}匹配元组
for (tuple <- Array(
(0, 1),
(1, 0),
(1, 1),
(1, 0, 1)
)) {
val result = tuple match {
// 第一个元素是 0 的对偶元组
case (0, _) => "0 ..."
// 第二个元素是 0 的对偶元组
case (y, 0) => "" + y + "0"
// 匹配任意对偶元组
case (a, b) => "" + a + b
case _ => "something else"
}
println(result)
}应用
映射变量
// 类似于 JS 解构赋值
var (id, name, age) = (1, "张三", 18)
println((id, name, age))
// 作为函数参数使用时,需要将函数的小括号变为大括号
// 并且使用 case 关键字
var list = List(("a", 1), ("b", 2), ("c", 3))
println(
list.map {
case (word, count) => (word, count * 2)
}
)
// for 循环中使用
val list = List((0,20),(1,1),(2,2))
// 遍历 k=0 且 v > 10 的对偶元组进行打印
for ((0, v) <- list if v > 10) {
println(v) // 20
}转换数据结构
val list = List(
(("张三", "语文"), 90),
(("张三", "数学"), 100),
(("李四", "英语"), 95)
)
println(
list.map {
case ((name, subject), score) => (name, (subject, score))
}
)隐式转换
Scala 中的隐式转换是一种将一个类型转换为另一个类型的机制,通过 implicit 关键字告诉编译器,当第一次编译出错时,尝试使用该关键字关联的隐式转换再次编译。这使得我们可以在不改变原有代码的情况下,通过新增隐式转换,达到修改一些逻辑的目的,符合开闭原则。
关于隐式转换查找顺序
编译器首先会在当前作用域中查找 T 类型的隐式转换,包括直接定义的和导入的,
如果没找到则再在类型 T 及和它有关联的类与对象中查找,这个关联体现在 extends、with、类型参数 (泛型)、外部类。
参考:Where does Scala look for implicits? - Stack Overflow
隐式函数
注意隐式转换与名称无关,只与参数类型和返回值类型有关,在同一个作用域中,不能存在 1 个以上的 A → B 隐式转换函数,因为编译器无法确认使用哪个。
def main(args: Array[String]): Unit = {
// 定义一个隐式转换函数,将Int类型转换为String类型
implicit def intToString(int: Int): String = int.toString
// 此处编译时会使用隐式转换
val message: String = 123
println(message.isInstanceOf[String])
println(message)
}
// 反编译后
public void main(final String[] args) {
String message = intToString$1(123);
.MODULE$.println(BoxesRunTime.boxToBoolean(message instanceof String));
.MODULE$.println(message);
}
private static final String intToString$1(final int int) {
return Integer.toString(int);
}
// 注意隐式转换函数不能嵌套,否则会递归
// 例如上面的 intToString 改为下面的代码,会直接导致 StackOverflowError
implicit def intToString(int: Int): String = {
val msg: String = 321
return int.toString
}可以通过隐式函数转换,将一个类转换为一个包装类,从而扩展其功能。
class Person(name: String) {
def printName(): Unit = {
println(s"my name is ${name}")
}
}
class PersonExt(person: Person) {
// 扩充功能
def desc(): Unit = {
person.printName()
println("I am a student")
}
}
def main(args: Array[String]): Unit = {
// 隐式转换
implicit def converter(person: Person): PersonExt = {
new PersonExt(person)
}
val p1 = new Person("zhangsan")
p1.printName()
// 编译器在此处将 p1 从 Person 转换为 PersonExt
p1.desc()
}隐式类
隐式类不能是顶级类,必须定义在类、伴生对象或包对象中,且构造方法有且只能有一个,可用于扩展类的功能。
object 隐式类 {
implicit class MyInt(var int: Int) {
// 给 Int 扩充了一个 ++ 方法
def ++ = {
int += 1
int
}
}
def main(args: Array[String]): Unit = {
// 编译时转换为 MyInt
print(1++)
}
}隐式参数与隐式值 (对象)
隐式值同样与名称无关,只与类型有关,即同一个作用域中相同类型的隐式值只能有一个。
优先级为 传值 > 隐式值 > 默认值;当隐式参数没有匹配到隐式值时,会使用默认值,如果没有默认值则会报错。
def main(args: Array[String]): Unit = {
// 声明为“隐式值”
implicit val name = "zhangsan";
// 声明为“隐式参数”,匹配隐式值
def printName(implicit name: String = "lisi"): Unit = {
println(name)
}
printName("wangwu") // wangwu
printName() // lisi
printName // zhangsan
}上下文界定
方法的隐式参数也可称为上下文参数,除非显示的在方法调用时传参,Scala 会查找可用的隐式值自动传递给方法。
上下文界定是泛型与隐式转换的结合,其实就是根据传参的类型,编译器匹配并绑定对应的隐式对象到方法参数中。
例如排序需要传递一个比较器,但对于常见的类型,其比较器是比较通用标准化的,这就可以声明比较器对象为隐式参数,
由编译器根据传参的类型自动匹配合适的比较器对象,并传递给方法参数。
def main(args: Array[String]): Unit = {
// 格式1:def f[T: B](a: T) 通过 implicitly[B[T]] 来获取隐式对象
// 表示根据传参的类型 T,上下文中必须要有一个 B[T] 的隐式对象
def f1[T: Ordering](a: T, b: T) = implicitly[Ordering[T]].compare(a, b)
// 格式2(建议使用):def f[T](a:T)(implicit arg:B[T]) 使用函数柯里化
def f2[T](a: T, b: T)(implicit ord: Ordering[T]) = ord.compare(a, b)
// 编译器会在上下文(隐式转换的作用域中)匹配隐式对象,自动绑定
/*
* scala.math.Ordering 中定义了隐式对象
* implicit object Short extends ShortOrdering
* trait IntOrdering extends Ordering[Int] {
* def compare(x: Int, y: Int) = java.lang.Integer.compare(x, y)
* override def reverse: Ordering[Int] = IntReverse
* }
*
* */
println(f1(1, 2))
// scala.math.Ordering 中定义了 implicit object Double extends DoubleOrdering
println(f2(1.0, 2))
}
// 反编译后长这样,可以看到方法的第三个参数就是上下文绑定的对象
public void main(final String[] args) {
.MODULE$.println(BoxesRunTime.boxToInteger(f1$1(BoxesRunTime.boxToInteger(1), BoxesRunTime.boxToInteger(2), scala.math.Ordering.Int..MODULE$)));
.MODULE$.println(BoxesRunTime.boxToInteger(f2$1(BoxesRunTime.boxToDouble(1.0), BoxesRunTime.boxToDouble(2.0), scala.math.Ordering.Double..MODULE$)));
}Maven 打包
参考:
- Scala with Maven | Scala Documentation (scala-lang.org)
- scala-maven-plugin – scala-maven-plugin (davidb.github.io)
<plugins>
<!--支持编译Scala-->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.8.1</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
<!--支持编译 Scala + Java-->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.8.1</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
<!--jar包,指定 MainClass-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.your-package.MainClass</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>