Overview
Apache ZooKeeper 是一个开源的分布式服务管理框架,它将复杂且容易出错的分布式一致性服务进行封装,提供了一系列高效可靠的接口供用户使用。可用于实现分布式锁、数据发布订阅、配置管理、注册中心等功能。
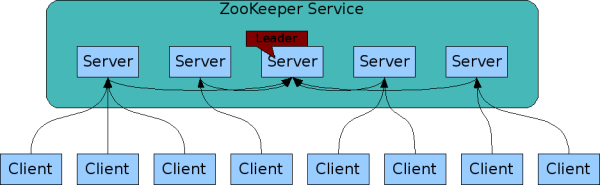
zk 集群中有 1 个 leader 和多个 follower 组成,集群中只要有半数以上的节点存活,就可以正常对外提供服务,所以 zk 集群适合奇数个节点。
zk 集群在 leader 选举时,无法对外提供服务,它保证来自同一个客户端的更新请求会被顺序执行,且更新具有原子性,要么成功要么失败。
环境搭建
- docker
docker pull zookeeper
docker run --name zk -p 2181:2181 -d zookeeper
docker run -it --rm --network container:zk zookeeper zkCli.sh -serverzk 是 Java 写的,需要配置正确 JAVA_HOME。
- 单机环境
# 解压
tar -zxvf /mnt/c/DevKit/zookeeper/apache-zookeeper-3.8.3-bin.tar.gz -C /opt/module/
# 重命名
mv apache-zookeeper-3.8.3-bin zookeeper-3.8.3
# 修改配置
cd conf
cp zoo_sample.cfg zoo.cfg
nano zoo.cfg
# 修改 dataDir=/opt/module/zookeeper-3.8.3/zkData
# 创建文件夹
mkdir -p /opt/module/zookeeper-3.8.3/zkData
# 启停 server
bin/zkServer.sh start
bin/zkServer.sh status
bin/zkServer.sh stop
# 启动 client
bin/zkCli.sh
# jps 验证
# ...
4222 QuorumPeerMain
# ...- 部分配置解释:
# The number of milliseconds of each tick
# 客户端与zk节点,zk节点之间 的心跳时间 ms
tickTime=2000
# The number of ticks that the initial synchronization phase can take
# 初始化时最多容忍的心跳次数
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
# leader 与 follower 同步心跳次数,超过该次数认为 follower 已死
syncLimit=5
# the directory where the snapshot is stored.
# 保存 zk 数据的目录
dataDir=/opt/module/zookeeper-3.8.3/zkData
# the port at which the clients will connect
clientPort=2181- 集群环境配置
# 在 zkData 目录创建名为 myid 的文件,保存该节点的编号
echo 1 > zkData/myid
# 在 zoo.cfg 中增加配置
server.1=ip1:2888:3888
server.2=ip2:2888:3888
server.3=ip2:2888:3888
# 其中 1 2 3 是 myid 中的编号
# 2888 是 leader 与 follower 之间同步信息的端口
# 3888 是 leader 选举时服务器之间通信的端口
# 最后分别启动
bin/zkServer.sh start- 启动后通过客户端连接
bin/zkCli.sh -server 127.0.0.1:2181ZNodes
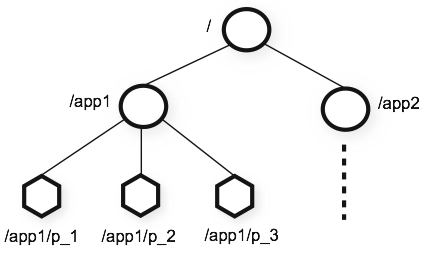
在 ZooKeeper 中使用类似文件系统目录的结构保存数据,称之为 znode,默认能够存储 1MB 的数据,有如下几种类型。
-
持久节点 (Persistent Node):创建后即使客户端会话结束也会一直存在;
- 创建命令:
create /path data - 使用场景:存储系统元数据存储、配置信息等需要持久化保存的数据
- 创建命令:
-
临时节点 (Ephemeral Node):与客户端会话绑定,会话结束节点自动删除;
- 创建命令:
create -e /path data - 使用场景:
- 实现服务发现(服务上线时创建,下线自动清除)
- 集群成员管理(判断节点存活状态)
- 分布式锁的实现
- 创建命令:
-
持久顺序节点 (Persistent Sequential Node):持久节点 + 自动追加顺序编号;
- 创建命令:
create -s /path data - 使用场景:
- 需要保持创建顺序的持久化数据
- 需要唯一命名的持久化资源分配
- 创建命令:
-
临时顺序节点 (Ephemeral Sequential Node):临时节点 + 自动追加顺序编号;
- 创建命令:
create -e -s /path data - 使用场景:
- 公平锁的实现(监听前一个节点的释放)
- 有序的临时任务队列
- 创建命令:
-
容器节点 (Container Node):当最后一个子节点被删除时,容器节点会被自动删除;
- 创建命令:
create -c /path data - 使用场景:
- 实现资源池模式
- 动态组成员管理
- 需要自动清理的空容器
- 创建命令:
-
TTL 节点 (TTL Node):可以设置节点的存活时间,超时后被自动删除;
- 创建命令:
create -t ttl /path data - 使用场景:
- 需要自动过期的临时数据
- 缓存数据的存储
- 限时任务分配
- 创建命令:
常用命令
help:显示所有命令;quit:退出客户端;create:创建 znode;-e临时;-s带序号;
ls:查看子节点;-w监听子节点变化;-s附加额外信息;
get:查看当前节点;-w监听子节点变化;-s附加额外信息;
set:设置当前节点的值;stat:查看节点状态;-w监听子节点变化;
delete:删除节点;deleteall:递归删除节点;
znode 信息解释:
# 创建一个节点,内容为字符串 my_data
create /zk_test my_data
# 修改数据为 zhangsan
set /zk_test zhangsan
# 查看该节点详情
[zk: localhost:2181(CONNECTED) 12] get -s /zk_test
# 该节点的数据内容
zhangsan
# 创建该节点事务ID
cZxid = 0x4
# 创建该节点的时间戳
ctime = Mon Jan 22 22:47:10 CST 2024
# 该节点最后更新时的事务ID
mZxid = 0x5
# 该节点最后更新时的时间戳
mtime = Mon Jan 22 22:51:04 CST 2024
# 该节点的子节点列表最后变化时(增删子节点)的事务ID
pZxid = 0x4
# 子节点版本号,增删子节点时自增
cversion = 0
# 该节点数据内容的版本号,数据修改一次则自增
dataVersion = 1
# acl 版本号
aclVersion = 0
# 如果是临时节点,则为 session id,否则为 0
ephemeralOwner = 0x0
# 该节点数据内容的长度
dataLength = 8
# 子节点数量,只统计一层不递归
numChildren = 0ZAB 协议
Quote
ZooKeeper 通过ZAB 协议(ZooKeeper Atomic Broadcast) 来保证分布式系统中数据最终一致性。
Leader 选举
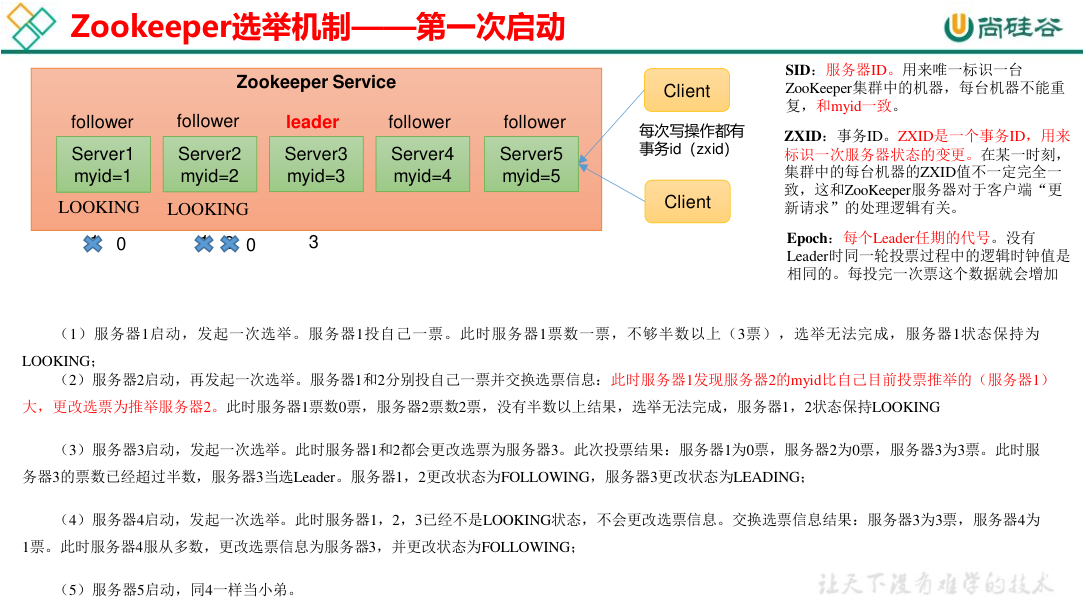
在 leader 选举过程每个节点不断做出最优选择并广播,最终所有节点达成一致。
zk 的事务 ID(zxid) 是一个 64 位的整形数据,其中高 32 位是 epoch 表示 leader 任期编号 (就像朝代一样),低 32 位是 xid,每进行一次写请求后 32 位自增,每完成一次选举,高 32 位也就是 epoch 加一。
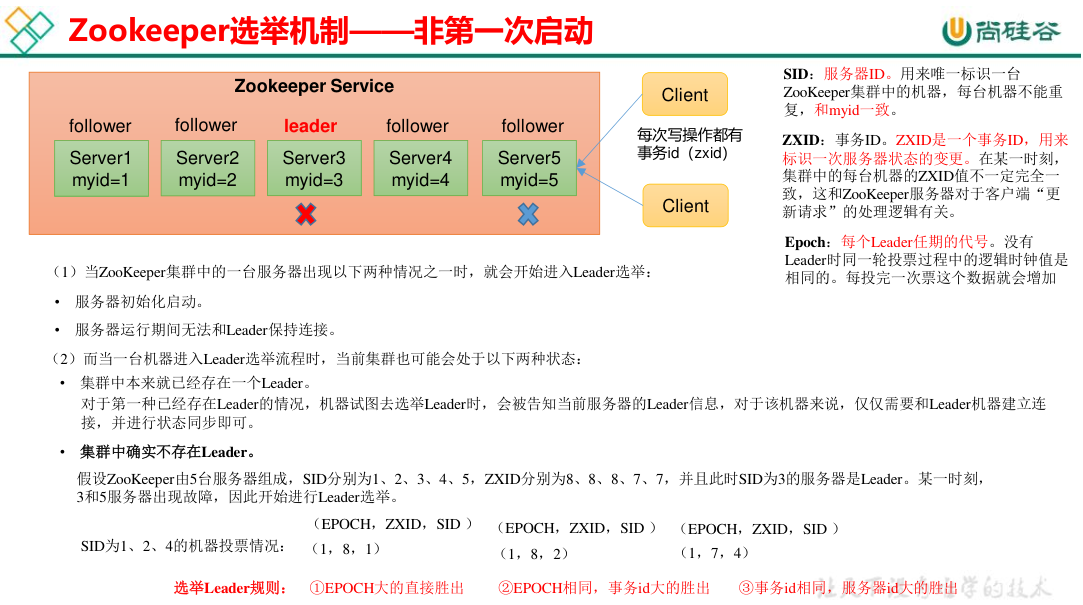
第一次启动时比较的是 myid,而非第一次启动时 (leader 宕机),原则是谁的数据最新则选谁为 leader,即 order by zxid, myid desc。
数据更新
- 客户端的写请求提交给 Leader,Leader 生成事务日志(Zxid)并广播给所有 Follower;如果客户端连接的是 Follower,则 Follower 会转发写请求到 Leader;
- Follower 收到写操作的消息先写一阶段日志,在返回确认消息给 Leader;
- 当 Leader 收到半数以上节点(包括自身)的写入确认后,提交事务,并通知所有 Follower 提交该事务;Leader 在提交事务后,向客户端发送写操作成功响应;
- Follower 在自己的节点上进行二阶段提交;
默认情况下,在此期间如果客户端连接到了某个还未提交该事务的 Follower 进行了读取操作,会读到未同步的旧数据。除非在读取前调用 sync() 确保获取最新的数据。
当客户端调用 sync() 时,ZooKeeper 会确保当前连接的节点(Follower 或 Leader)与 Leader 同步到最新的事务状态,客户端的后续读操作将基于同步后的最新状态,避免读取到旧数据。